Sub-Redes e Super-Redes IPv4Tradução de endereços (NAT)Professor Adjunto do Departamento de Engenharia Informática do ISEP IntroduçãoInicialmente o espaço de endereçamento era largamente superior a qualquer tipo de necessidade em qualquer instituição isoladamente. À medida que as várias redes IPv4 foram interligadas, vindo a formar o que hoje é conhecido por "internet", começou a avolumar-se um grave problema porque todos os endereços tinham de ser únicos. O espaço de endereçamento começou a não ser suficiente para as crescentes necessidades. Para além dos espaço de endereçamento limitado (32 bits), as regras de endereçamento que dividem as redes em classes revelaram-se também muito restritivas, levando ao "desperdicio" de muitos endereços, pois o aproveitamento de cada rede apenas se verifica para um número exacto de nós, que raramente corresponde ŕs situações concretas. Para resolver este problema começou mais tarde o desenvolvimento do IPv6, com endereços de 128 bits. O desenvolvimento do IPv6 foi algo demorado e tiveram de ser encontradas soluções mais expeditas para manter o IPv4 no activo, elas são fundamentalmente duas:
Apesar de estas soluções serem consideradas temporárias, resolveram de forma muito eficięnte o problema da escasses de endereços do IPv4 e acabaram por retardar a adopção do IPv6, que ainda não é muito usado. Sub-Redes e Super-RedesTrata-se de uma mesma técnica que consiste na manipulação da mascara de rede, inicialmente as mascaras de rede possuiam apenas tręs valores possíveis correspondentes ŕs tręs classe de rede:
Note-se ainda que estas máscaras de rede estão implicitamente associadas aos endereços porque os dois primeiros bits do endereço identificam a classe.
A manipulação da mascara de rede consiste no avanço ou recuo da mascara, no primeiro caso criam-se sub-redes, no segundo caso criam-se super-redes. Divisão em sub-redes O avanço da mascara consiste em activar bits (passar ao valor 1) imediatamente ŕ direita dos bits que estão activos na mascara "normal". Isso significa que o número de bits usados para identificar os nós em cada rede diminui, teremos então redes mais pequenas, mas por outro lado teremos mais bits para identificar a rede, o que significa que teremos mais redes (sub-redes). Agrupamento em super-redes O recuo da mascara consiste em desactivar bits (passar ao valor 0) imediatamente ŕ esquerda dos bits que estão inactivos na mascara "normal". Isso significa que o número de bits usados para identificar os nós em cada rede aumenta, teremos então uma rede de maior dimensão (super-rede), mas por outro lado teremos menos bits para identificar a rede, o que significa que teremos menos redes. (JavaScript) Cuidados na manipulação da mascara de rede A manipulação da mascara de rede tem um impacto enorme sobre o aproveitamento dos endereços, um dos exemplos mais evidente é a interligação de nós intermédios através de ligações dedicadas: Tratando-se de nós IP é necessário definir uma rede IP sobre a ligação dedicada, sem criar sub-redes, a única solução era atribuir a essa ligação uma rede de classe C. Isso constituia um despedicio enorme de endereços, já que dos 254 endereços de nó de uma rede de classe C, apenas eram usados 2. Usando sub-redes podemos avançar a mascara até que apenas fiquem 2 bits com o valor 0 (mascara FF.FF.FF.FC), nestas condições, uma única rede de classe C permite criar 64 sub-redes com capacidade para dois nós cada. O exemplo apresentado ilustra também outro facto, em termos teóricos a divisão em sub-redes conduz a um desperdicio de endereços, dos 254 nós de uma rede de classe C passamos a ter 64 redes com dois nós cada, ou seja 128 nós. Este facto deve-se ao facto de em cada rede estarem reservados o endereço do nó 0 (endereço da rede) e o endereço de nó com os bits todos 1 (endereço de "broadcast"). Para além destes dois endereços, a definição de uma rede implica também a ligação a um encaminhador ("router") o que ocupa ainda mais um endereço. Este desperdicio é meramente teórico pois é largamente compensado pela melhor adaptação do tamanho das redes ŕs realidades existentes. A manipulação da mascara de rede deve ser realizada de uma forma consciente: O primeiro cuidado fundamental é garantir que nunca existe sobreposição das redes (endereços comuns). - Ao definir uma super-rede vamos ocupar espaço de endereçamento de várias redes. Por exemplo, em redes de classe C, para criar uma super-rede por recuo de um bit na mascara de rede será necessário usar as duas redes de classe C correspondentes aos dois valores possíveis para esse bit, para recuar 2 bits serão necessárias as 4 redes de classe C correspondentes aos valores possiveis desses bits. - Na divisão em sub-redes colocam-se os mesmos problemas, embora a separação das várias sub-redes seja normalmente clara, se forem aplicadas simultanemente várias mascaras a uma mesma rede é necessário ter cuidado para evitar qualquer tipo de sobreposição. Problema exemplo: necessitamos de 6 ligações dedicadas a 6 redes com cerca de 20 nós cada:  Uma rede de classe C é suficiente:
As tabelas seguintes mostram os valores binários do último octeto, para as várias sub-redes, com a parte de nó preenchida com "?". Pode-se verificar que não existem sobreposições, e por isso a solução é válida. Aplicando a mascara FF.FF.FF.E0 obtemos 8 redes com capacidade para 30 nós:
Se garantirmos que (por exemplo) a última rede não é usada (.225 a .254), podemos aplicar-lhe a mascara FF.FF.FF.FC e deste modo obter 8 redes com dois nós cada:
Tomando como exemplo a rede de classe C 193.201.232, a solução com todos os endereços especificados poderia ser: 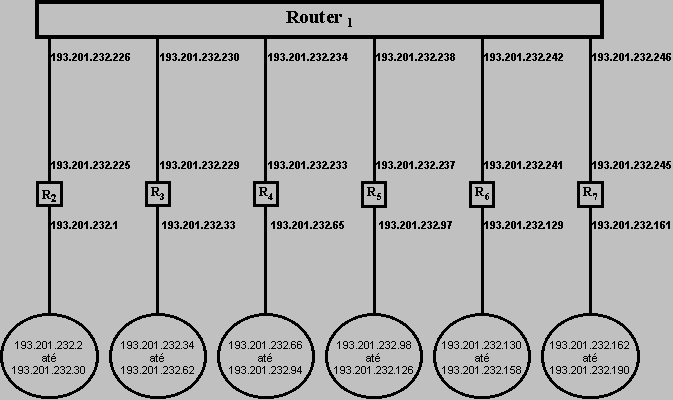 Note-se ainda o respeito por um principio prático importante, segundo o qual devemos deixar sempre disponíveis endereços para ampliação da infraestrutura, a curto prazo. Neste caso particular, além de cada rede poder ser ampliada até 29 nós, existe uma rede de reserva, bem como endereços para a respectiva ligação dedicada. Este tipo de soluções é bastante flexivel, mas deve ser sempre validado com cuidado, tal como aqui se usam duas mascaras diferentes sobre uma mesma rede de classe C, nada nos impede de usar um qualquer número de mascaras distintas sobre uma qualquer rede de qualquer classe. O que é importante é que não existam endereços que pretençam a mais do que uma rede. O segundo aspecto critico na manipulação das mascaras de rede consiste em compreender para que servem as mascaras e deste modo perceber o impacto que a sua manipulação vai ter. As mascaras de rede servem para extrair de uma forma expedita a parte de rede de um dado endereço, para isso é efectuado o "AND" lógico, bit-a-bit com a mascara de rede. Esta operação é o primeiro passo para o encaminhamento correcto dos dados IP que se baseia sempre unicamente na parte de rede:
Como é facil deduzir, para que as manipulações das mascaras de rede funcionem sem problemas é necessário que em todos os nós onde as respectivas redes são definidas estejam sempre presentes as máscaras correctas. Contudo este tipo de informação não pode normalmente ser propagada para os encaminhadores da "internet", isto que dizer que estes encaminhadores trabalham na suposição de que as mascaras não são manipuladas. Podemos por isso afirmar que a manipulação das mascaras de rede é uma definição apenas com efeito local. Isto significa que, por exemplo, não é possível dividir uma rede em duas sub-redes e ligar as mesmas a dois pontos distintos da "internet". As sub-redes, sob o ponto de vista da "internet", tęm de estar agrupadas no mesmo ponto de acesso, porque sob o ponto de vista da "internet" continuam a ser uma única rede. Tradução de endereços (NAT)O manuseamento das mascaras de rede (divisão em sub-redes e agrupamento em super-redes), permite eliminar os grandes desperdicios de endereços que de outra forma seriam inevitáveis. O número de endereços disponibilizado desta forma acabou por se revelar insuficiente para a grande expansão da "internet" e o que verdadeiramente "salvou" o IPv4 de uma substituição rápida pelo IPv6 foi a tradução de endereços. Ao observar o tipo de nós finais ligados ŕ "internet", facilmente se constata que a grande maioria assume unicamente o papel de cliente, ou seja apenas recebem respostas aos pedidos por eles formulados, nunca recebem pedidos provenientes da "internet". Os nós finais nestas condições não necessitam de estar directamente ligados ŕ "internet", para isto ser possível o "router" que assegura a ligação é substituido por servidores "proxy" de aplicações. 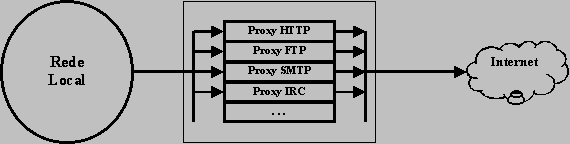 Os servidores "proxy" tęm como finalidade optimizar o acesso aos servidores na "internet", para isso colocam-se numa posição de intermediários entre cliente e servidor. Por exemplo quando um cliente na rede local (configurado para usar o servidor "proxy"), usa um "browser" para abrir uma página "WEB":
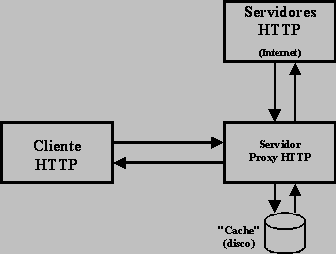 Como se pode verificar os clientes não necessitam de ter acesso ŕ "internet", basta-lhes aceder ao servidor "proxy". Por seu lado o servidor "proxy" necessita de acesso ŕ "internet". Nestas condições os podemos dizer que os endereços dos clientes são privados porque nunca comunicam directamente com a "internet", ou seja os pedidos relativos a estes clientes circulam na "internet" tendo como endereço de origem o endereço do servidor "proxy", do mesmo modo as respectivas respostas tęm como destino o endereço do servidor "proxy", os endereços dos clientes nunca transparecem para a "internet". Sob o ponto de vista da "internet" estes clientes não existem. Numa configuração deste tipo a rede local com endereços privados é também conhecida por rede privada, teóricamente numa rede privada podem ser usados quaisquer endereços, contudo para evitar consequencias para a "internet" no caso de haver uma falha e "passarem" endereços privados para a "internet" foram estabelecidas determinadas gamas de endereços para este efeito:
Uma vez que estes endereços não estão atribuidos a ninguem, o facto de por acidente se deixarem escapar pacotes com estes endereços não deverá afectar terceiros. As redes privadas baseadas em "proxies" de aplicação são perfeitamente funcionais, mas na prática apenas são aconselháveis para ambientes em que o leque de aplicações de rede usadas é muito limitado. Para que uma rede privada baseada em "proxies" de aplicação funcione é necessário um servidor "proxy" (processo/aplicação) para cada protocolo de aplicação usado, além disso a utilização deste tipo de "proxy" não é directa, isto é cada protocolo de aplicação usado e respectivo "software" cliente de rede tem de suportar a utilização de "proxy". Se para alguns protocolos como o HTTP e o FTP o suporte de "proxy" é um dado adquirido, para outros protocolos isso nem sempre acontece. Apesar destes inconvenientes os "proxies" de aplicação tęm algumas vantagens únicas:
NAT - Proxy Transparente Os "proxy" transparentes funcionam a um nível muito inferior, em lugar do nível de aplicação trabalham no nível de rede ou transporte, ao contrário dos anteriores assemelham-se muito a um encaminhador ("router"). Os "proxies" transparentes encaminham pacotes (Ex.: "datagramas" UDP) de forma absolutamente idęntica ŕ de um vulgar "router", contudo manipulam os endereços de origem e destino, algo que um "router" "normal" não faz. Deste facto provem a designação "Network Address Translation" (NAT). A manipulação dos endereços tem como objectivo "esconder" uma ou várias redes (privadas) "por trás" de um ou vários endereços oficiais. 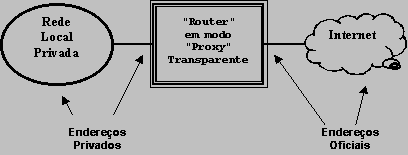 Para evitar que os endereços privados cheguem ŕ rede oficial ("internet"), o "proxy" transparente substitui os endereços de origem de todos os pacotes que são enviados para a rede oficial pelo seu próprio endereço oficial. Para manter a capacidade de encaminhar os dados para o endereço de origem correcto na rede privada usa-se um artificio baseado nos números de porto, imagine-se que um cliente na rede privada envia um pedido para a "internet":
Com este modo de funcionamento, nem cliente, nem servidor se apercebem do que se está a passar, esta técnica é portanto independente dos protocolos de aplicação, destas caracteristicas provém a designação "transparente". Note-se que a tradução de endereços passa-se únicamente na interface ligada ŕ rede oficial e excluindo as manipulações realizadas nessa interface, todo o restante funcionamento é o de um "router" "normal". 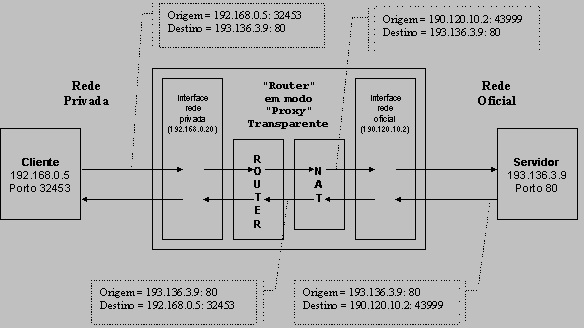 Note-se que estão em jogo duas traduções de endereços:
NAT estático Como foi visto, quando os pedidos são originários dos clientes que se encontram na rede privada, a tabela NAT é criada automaticamente. Estas entradas na tabela NAT servem para indicar que a chegada de dados a um dado porto da interface externa deve ser redireccionada (DNAT) para um dado número de porto e endereço IP na rede privada. Sendo isto verdade, então também será possível definir estáticamente entradas DNAT nessa tabela e com isso conseguimos facultar o acesso externo a servidores na rede privada. Cada uma destas entradas estáticas deverá conter:
Os clientes residentes na "internet" apenas podem contactar estes servidores usando o endereço IP oficial que assegura a ligação externa do "router". Quando chega um pedido a um "porto" nestas condições, vai passar-se o seguinte:
Sob o ponto de vista do cliente, localizado na "internet", aparentemente está a comunicar com um servidor que se encontra localizado na interface externa do "router". Continuam a existir duas traduções de endereços, mas agora em ordem inversa:
A definição de entradas estáticas DNAT permite facultar o acesso a vários servidores no interior da rede privada, contudo estes servidores terão de ser de tipos diferentes para que usem diferentes números de porto e assim possam ser distinguidos na interface externa. Se pretendermos facultar acesso a vários servidores do mesmo tipo na rede privada, o problema complica-se. Para facultar acesso a vários servidores do mesmo tipo terá de ser usado outro factor além do número de porto, pois este será igual para todos estes servidores. A técnica mais simples consiste em atribuir mais do que um endereço oficial ŕ interface externa do "router", deste modo torna-se simples distinguir os vários servidores no interior da rede privada, cada endereço oficial corresponde a um servidor distinto. As entradas estáticas DNAT passam então a conter:
|