
Conceitos diferentes:
Pipeline é uma forma de implementação de microprocessadores, pelo que pode ser usado para implementar microprocessadores que não se caracterizem como RISC.
No entanto, um dos elementos mais habitualmente usados para identificar um processador RISC é a existência de pelo menos um pipeline. Contudo existem processadores RISC que não têm pipeline (PTSC Ignite) e outros que não são RISC e que têm pipeline (Intel Pentium, é um processador CISC no que respeita ao seu conjunto de instruções, mas traduz essas instruções para um conjunto de instruções outras RISC, que são usadas internamente pelo pipeline.) .
O conceito de processador RISC baseia-se na premissa de que será menos eficiente executar uma instrução complexa do que executar o conjunto de instruções simples equivalente.
Assim, os processadores RISC têm por objectivo simplificar o conjunto de instruções em diversas dimensões por forma a maximizar esta premissa.
Para isso, um processador RISC caracteriza-se por:
O processamento de uma instrução é composto pelo menos por cinco fases:
O resultado é um pipeline de cinco estágios:

Como o estágio de instruction decode (descodificação) não necessita de aceder à memória (recurso partilhado), pode ser realizado em simultâneo com a fase de operand fetch (que usa a memória). O resultado é um pipeline com 4 estágios.

Este corresponde a uma abordagem minimalista e original, mas hoje em dia os pipeline não se limitam a 4 ou cinco estágios, mas podem chegar a 20 ou 30 estágios (Intel Pentium 4).
O princípio operacional dum pipeline é que podem estar em processamento várias instruções em simultâneo, pois cada um dos estágios é logicamente independente dos outros.

O resultado é que em execução óptima, o processador executa até uma instrução por ciclo de relógio, mesmo que cada instrução demore mais do que um ciclo de relógio a ser processada.
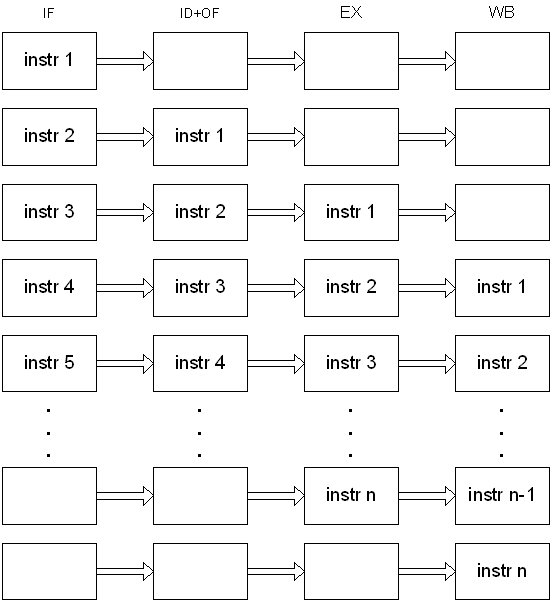
Portanto, teoricamente e na melhor das hipóteses, é possível executar uma instrução por cada ciclo de relógio, menos os ciclos iniciais em que os estágios não são completamente utilizados em processamento.
Ou seja:
c = i + e - 1
No entanto, para que todo o conceito/processo funcione é necessário que determinadas restrições se verifiquem. Nomeadamente, é prioritário que todas as instruções permaneçam em cada estágio o mesmo tempo, para que:
Porque o processamento é diferente de estágio para estágio, para que o processo ocorra num único ciclo de relógio é necessário analisar o problema a resolver e encontrar soluções convenientes.
Problema:
Solução:
Problema:
Solução:
Problema:
Solução:
Problema:
Solução:
Problema:
Solução:
Portanto, é fundamental que sejam observadas as seguintes restrições:
No entanto, este conceito de processamento tem alguns problemas, motivados pelo facto de estarem em processamento várias instruções em simultâneo.
São identificados dois tipos de problemas:
Considere-se o código seguinte:
mov ax, var1
mov bx, var2
add ax, bx
instr4
que corresponde à seguinte representação de execução:
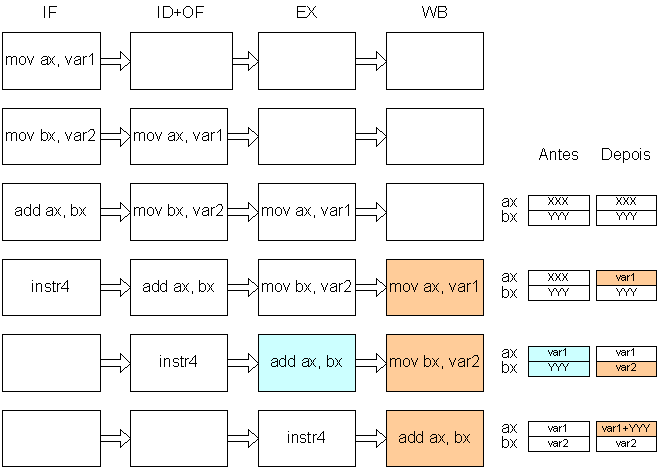
No estágio de execução da instrução add ax, bx, o valor de bx não é o correcto, pois a instrução anterior (mov bx, var2) ainda não escreveu o valor no registo bx.
Existem duas soluções possíveis:
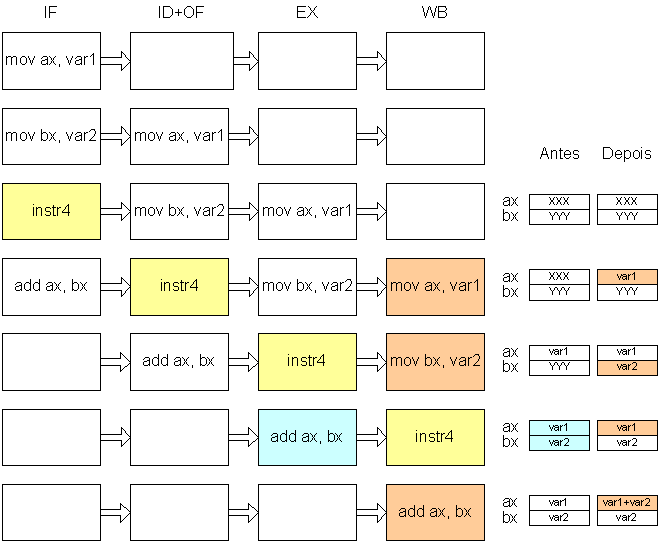
A solução de “forwarding” corresponde a fazer o valor passar directamente para o andar de execução (ou outro) sem passar pelos registos.
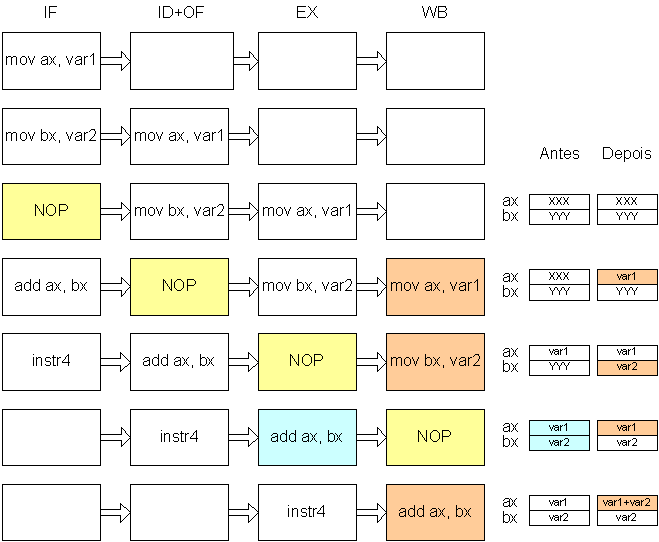
A solução de “interlocking” corresponde a fazer parar a instrução seguinte até que o valor correcto dos operandos esteja disponível. Assim, o exemplo anterior teria a seguinte execução:

A solução por software implica um de dois estratagemas:
Quando uma instrução de salto (branch) está a ser executada, já a seguinte também está a ser executada. Mas a instrução a executar a seguir é dependente do resultado da instrução de branch, pelo que não é possível antes disso determinar qual a instrução seguinte.
Considere o exemplo seguinte:
inicio:
mov cx, var1
mov dx, var2
mov ax, var3
mov bx, var4
% calcula o menor de dois valores e coloca em ax
cmp ax, bx
jle fimteste
bxmenor:
mov ax, bx
fimteste:
add cx, ax
sub dx, ax
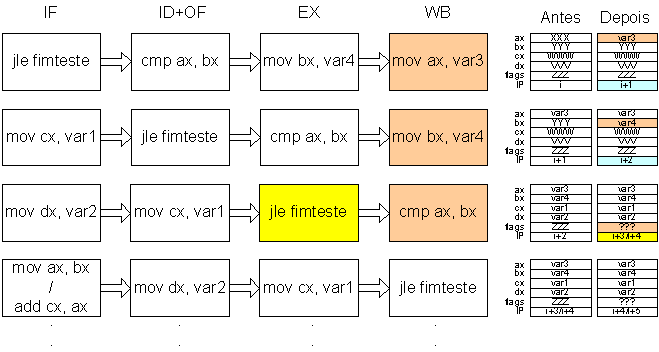
A execução corresponde ao modelo seguinte, considerando que o processador tem e aplica o mecanismo de “forwarding”:

Algumas instruções irão portanto ser processadas sem que haja garantias de que devam ser executadas. No caso de não deverem ocorre uma “bubble”. É o caso das instruções mov ax, bx (corresponde a colocar em ax o menor valor entre ax e bx) e add cx, ax (corresponde ao processo a seguir ao cálculo do menor valor). Ambas irão ser iniciadas independentemente do resultado da instrução “jle fimteste”.
Em função do resultado da instrução jle fimteste, duas hipóteses existem:
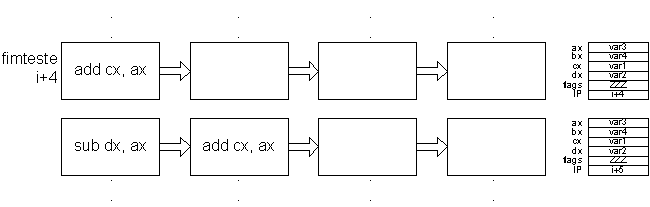
Os efeitos do processamento errado duma bubble têm de ser desfeitos (penalty), o que causa complicações à gestão do pipeline. Esta não é normalmente uma solução interessante ou fácil de implementar, pelo que é evitada.
O ponto de partida da solução é o denominado “branch delay slot”, a tal "bubble", que pode ter comprimento de 1 ou mais ciclos. Um branch delay slot corresponde a um ciclo de relógio (slot) em que não é iniciada uma nova instrução por causa dum branch condicional. O comprimento do branch delay slot varia de processador para processador, e quanto mais cedo a decisão de salto for tomada, menor será o seu comprimentos e portanto menor será a penalização. No caso anterior o comprimento da bubble é 2 (decisão sbore o branch é tomada no terceiro estágio do pipeline), enquanto no DLX é de 1(decisão tomada no segundo branch). Há processadores cujo comprimento do delay slot é de 5-10 ou mesmo mais slots, mas como a frequência de relógio é muito elevada (muitos estágios, frequência elevada), as penalizações acabam por não ser maiores que nalguns processadores em que o branch delay slot tem comprimento menor mas cujo ciclo é maior que nos outros.
Existem várias potenciais soluções:
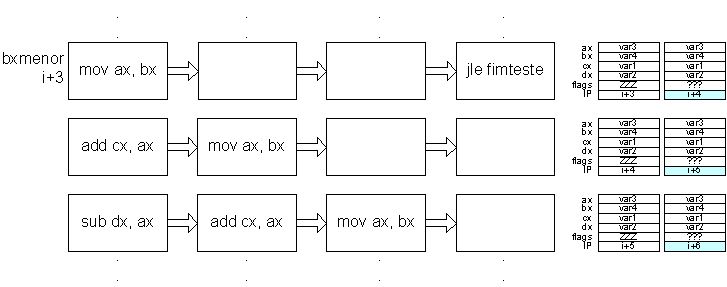
No caso do código anterior, seria possível definir uma instrução de “branch and execute” que executasse as instruções mov cx, var1 e mov dx, var2 nos 2 branch delays slots considerados anteriormente.
| com branch condicional | com branch e execution |
| inicio: mov cx, var1 mov dx, var2 mov ax, var3 mov bx, var4 % calcula o menor de dois valores e coloca em ax cmp ax, bx jle fimteste bxmenor: mov ax, bx fimteste: add cx, ax sub dx, ax |
inicio: mov ax, var3 mov bx, var4 % calcula o menor de dois valores e coloca em ax cmp ax, bx jle fimteste mov cx, var1 mov dx, var2 bxmenor: mov ax, bx fimteste: add cx, ax sub dx, ax |
Estas instruções podem ser usadas pois não provocam dependências nas seguintes (mov ax, var3 e mov bx, var4) pois os seus resultados só vão ser usados em add cx, ax.
Portanto, o “branch and execute” corresponde em muitas situações a uma reordenação de instruções sem a necessidade de termos dois saltos.
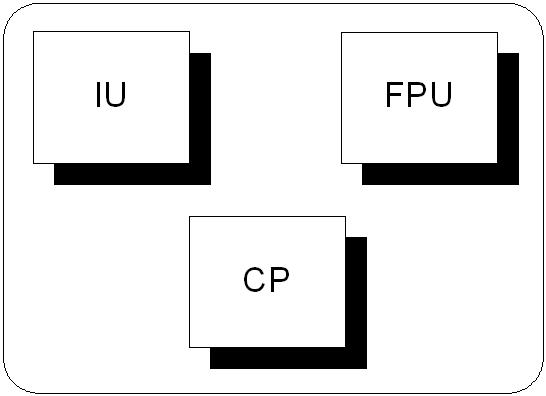
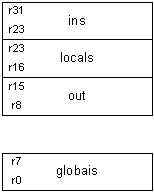
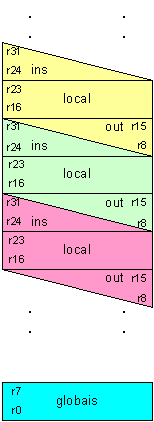
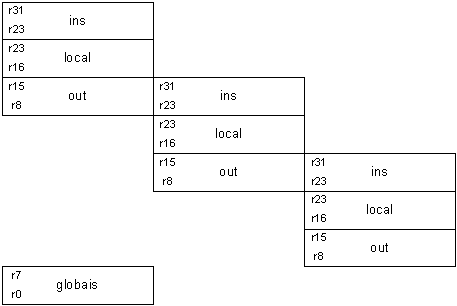
Originalmente a arquitectura Alpha é caracterizada por:
Outras características tão ou mais importantes:
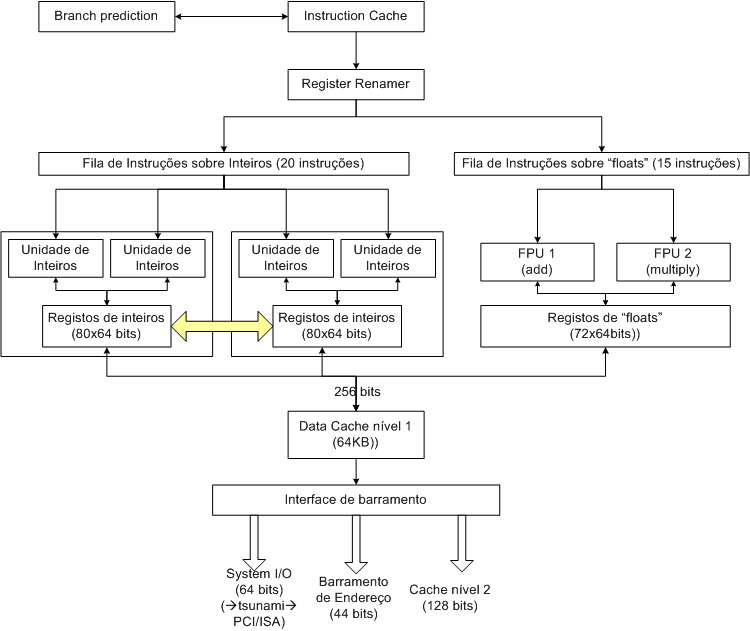
Pipeline com muitos estágios.
Quando existe mais do que uma unidade de execução no processador.
Normalmente a existência de mais do que uma unidade de execução está associada a processadores RISC (com pipeline), mas o número de unidades de execução é independente do número de pipelines.
Determina qual o caminho mais provável que o teste+salto irá tomar. Há várias formas de "branch prediction", nomeadamente:
Ordenar/Executar as instruções em função do resultado do branch prediction.
mov ax,var1
mov bx,var2
add ax,bx
; as instruções seguintes não dependem das anteriores
; portanto podem ser executadas fora da ordem
mov cx,var4
mov dx,var5
add cx,dx
mov var6,cx
mov ax,var1
mov bx,var2
add ax,bx
mov var3,ax
; as instruções seguintes não dependem das anteriores
; mas estão a usar os mesmos registos
se usarmos um mecanismo de “register renaming” então as
; instruções usarão outros registos e já serão executadas “fora da ordem”
mov ax,var4
mov bx,var5
add ax,bx
mov var6,ax
Local de reserva dos resultados das instruções, antes de serem colocados ordenadamente segundo o programa original nas suas localizações definitivas.
Também denominadas filas de espera de instruções.