![]()
![]()
![]()
Máquinas de Pilha - Arquitecturas de 32 bits
As arquitecturas de 16 bits são suficientemente poderosas para uma grande
variedade de aplicações, especialmente em programas embutidos. No entanto,
existem certas aplicações que necessitam do poder de cálculo extra que
oferece um processador de 32 bits, tais como uso intensivo de operações
aritméticas de 32 bits, grande espaço de endereçamento de memória ou
operações em vírgula flutuante.
Um dos maiores desafios que surgiram no desenvolvimento de máquinas de pilha de
32 bits foi a gestão das pilhas. Máquinas com o NC4016 tinham duas memórias
de pilha separadas fora do processador. Isto exigia 64 pinos extra só para a
pilha de dados, tornando esta abordagem impraticável para implementações com
custo reduzido. O FRISC3 resolvia este problema mantendo dois buffers de topo da
pilha dentro do chip e usando os pinos da RAM normal para passar os elementos da
pilha de e para a memória do programa. O RTX 32P reserva um grande espaço do
chip para a movimentação dos elementos das pilhas.
O Harris Semiconductor RTX 32P é um processador de 32 bits da família Real
Time Express. É uma implementação do WISC CPU/32 numa célula CMOS.
O desenvolvimento deste processador teve como principal objectivo a
flexibilidade. As pilhas de dados e de endereços de retorno encontram-se dentro
do chip, bem como uma grande quantidade de memória para microcódigo. Esta
grande quantidade de memória forçou o uso de dois chips.
Uma importante característica é que à medida que a velocidade do processador aumenta a ALU pode ser acedida duas vezes para cada acesso de memória fora do chip. Assim o RTX 32P executa duas microinstruções por cada acesso de memória, incluindo obtenção de instruções. Cada instrução demora dois ou mais ciclos de relógio, com diferentes microinstruções executadas a cada ciclo de relógio.
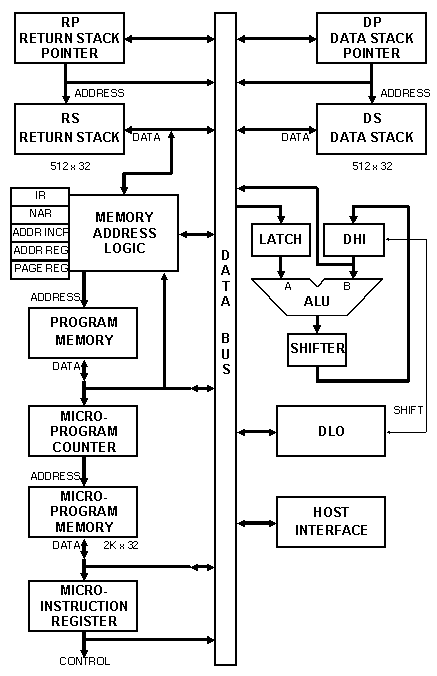
A pilha de dados e a pilha de endereços de retorno são implementadas em hardware, com 512 elementos de 32 bits cada. Os ponteiros das pilhas podem ser lidos e escritos pelo sistema proporcionando uma forma eficiente de aceder a elementos no fundo da pilha.
A ALU possui um registo DHI para armazenar os resultados intermédios. Este
registo actua como buffer do elemento de topo da pilha, o que significa
que o ponteiro para a pilha de dados endereça o que é o segundo elemento de
topo para o programador.
Uma operação com os dois elementos de topo da pilha pode ser efectuada num
único ciclo, sendo o valor de entrada A o elemento de topo da pilha, obtido a
partir do registo DHI e o valor de entrada B o segundo elemento de topo da pilha
de dados.
A unidade Latch pode ser usada para reter dados durante um ciclo de relógio,
acelerando as operações de troca de valores entre o registo DHI e a pilha de
dados.
O registo DLO armazena resultados temporários de uma instrução. Tanto o DHI como o DLO são registos de deslocamento, permitindo um deslocamento de 64 bits para multiplicações e divisões.
A unidade Host Interface, que está fora do chip, é usada para ligação ao computador anfitrião.
O RTX 32P não tem program counter. Cada instrução contém o endereço da próxima instrução a ser executada ou refere-se ao elemento de topo da pilha de endereços de retorno. O bloco Memory Address Logic contém um registo Next Address Register (NAR) que guarda o ponteiro para a próxima instrução. O Memory Address Logic usa o elemento de topo da pilha de endereços de retorno para endereçar memória para os retornos das subrotinas e usa o registo de endereço RAM (ADDR REG) para ler e guardar valores na memória. Como a pilha de endereços de retorno e a unidade Memory Address Logic podem ser isolados do bus de dados, chamadas e retornos de subrotinas e saltos incondicionais podem ser efectuados em paralelo com outras operações, conseguindo em certos casos um custo zero para o sistema.
A Microprogram Memory é uma memória de leitura e escrita, existente dentro do chip, endereçada por 256 páginas com 8 palavras cada. Cada opcode é alocado na sua própria página de 8 palavras. O Microprogram Counter fornece um endereço de página de 9 bits.
Para descodificar as instruções o RTX 32P coloca no Microprogram Counter o opcode de 9 bits e usa-o como endereço da página para a Microprogram Memory.
O Microinstruction Register (MIR) guarda o valor da Microprogram Memory, permitindo que a próxima microinstrução seja acedida a partir da Microprogram Memory em paralelo com a execução da microinstrução corrente. O MIR impõe o limite mínimo de dois ciclos de relógio para a execução das instruções. Se uma instrução pode ser completada num único ciclo de relógio, uma segunda instrução NOP deve ser adicionada para permitir que a próxima instrução aceda correctamente ao registo MIR.

O RTX 32P tem apenas um formato para as suas instruções. Todas contêm um opcode de 9 bits que é usado como número da página para a memória de microcódigo. Têm um controlo de fluxo do programa de 2 bits (bits 0 e 1) que invoca um salto incondicional, uma chamada a uma subrotina ou um retorno de uma subrotina. Nos casos de uma chamada a uma subrotina ou salto incondicional, os bits 2-22 são usados para especificar os 21 bits mais altos de um endereço de destino de 23 bits, limitando os tamanhos dos programas a 8 Mb a menos que o registo de página no Memory Address Logic seja usado com instruções especiais de salto e de chamada de subrotinas. As leituras e escritas de dados vêem a memória como uma espaço de endereçamento contínuo de 4 Gb.
Sempre que possível o compilador do RTX 32P compacta um opcode seguido de uma chamada a uma subrotina, retorno ou salto numa única instrução. Quando isto não é possível existem duas possibilidades: na primeira, um NOP é compilado juntamente com uma chamada, salto ou retorno. Na segunda, juntamente com o opcode é compilado um salto para a próxima instrução.
Como o RTX 32P usa RAM para a memória de microcódigo, o microcódigo pode ser completamente alterado pelo utilizador. O conjunto de instruções do RTX 32P pode ser estendido pelo utilizador para incorporar outras primitivas de manipulação da pilha que sejam necessárias numa determinada aplicação.
Cada instrução invoca uma sequência de microinstruções na página da Microprogram Memory correspondente ao opcode de 9 bits da instrução. Tal como para as instruções apenas existe um formato para as microinstruções que é dividido em campos distintos para controlar diferentes aspectos da máquina. A simplicidade da abordagem das máquinas de pilha e o hardware do RTX 32P leva a um formato simples das instruções de microcódigo. Cada microinstrução é executada a cada ciclo de relógio, com duas ou mais microinstruções executadas para cada macroinstrução da máquina.
O formato das microinstruções é o seguinte:

Bits 0-3 especificam a fonte do bus de dados.
Bits 4-7 especificam o destino do bus de dados.
Bits 8 e 9 indicam o incremento ou decremento do ponteiro para a pilha de dados.
Bits 10 e 11indicam o incremento ou decremento do ponteiro para a pilha de
endereços de retorno.
Bits 12 e 13 controlam o descolamento no output da ALU.
Bits 14 e 15 não são usados.
Bits 16-20 controlam a função da ALU.
Bit 21 indica carry_in/shift_in
Bits 22 e 23 controlam a leitura e deslocamento do registo DLO.
Bits 24-29 são usados para calcular um offset de 3 bits na página de
microcódigo para obter a próxima instrução.
Bits 24-26 seleccionam uma de oito condições para formar o bit mais baixo do endereço.
Bits 27 e 28 são usados como constantes para gerar os dois bits de maior ordem do endereço.
Bit 29 pode ser usado para incrementar o MPC para permitir usar mais do que 8 localizações de memória de microcódigo.
Bit 30 inicia a descodificação da próxima instrução.
Bit 31 controla o incremento do endereço de retorno para ser usado como
contador na memória para acesso a blocos de dados.
O relógio do RTX 32P corre ao dobro da velocidade que a memória principal pode ser acedida, obtendo dois ciclos de relógio para cada ciclo de memória e um mínimo de dois ciclos de relógio por instrução.
O RTX 32P não tem suporte directo de saltos condicionais em hardware. Os saltos condicionais são implementados usando o opcode 0BRANCH em combinação com uma chamada a uma subrotina para o destino do salto. Esta chamada à subrotina é processada pelo hardware em paralelo com a avaliação do elemento de topo da pilha. Se este elemento tiver o valor zero então o salto é efectuado. Se o salto for tomado, é retirado o elemento de topo da pilha de endereços de retorno, convertendo a chamada à subrotina num salto normal e a execução continua. Se o salto não for tomado o microcódigo retira o elemento de topo da pilha de endereços de retorno e usa esse valor para obter a próxima instrução a ser executada a seguir ao salto, efectuando um retorno imediato de uma subrotina.
Este processador permite um rápido acesso a qualquer localização de memória. Mesmo com um formato de instrução com 0 operandos é possível não especificar o endereço da variável. Um opcode especial é compilado com uma chamada a uma subrotina, onde o endereço da subrotina é na verdade o endereço da variável que se pretende obter. O microcódigo obtém o valor da variável e força um retorno de uma subrotina antes desse valor ser executado como uma instrução.
O RTX 32P suporta tratamento de interrupções, incluindo interrupções em overflow/underflow das pilhas de dados e endereços de retorno. A técnica normalmente usada é colocar ou retirar da memória metade do conteúdo da pilha existente no chip, permitindo que os programas usam profundidades da pilha arbitrárias. Tipicamente, com um buffer em hardware de 512 elementos os programas em Forth num passam por um overflow.
O RTX 32P é implementado numa célula CMOS com dois chips. O chip de dados, num LCC de 84 pinos, inclui a ALU, a pilha de dados e memória de microcódigo. O chip de controlo, que contém o resto do sistema, está empacotado dentro de um PGA de 145 pinos.
O RTX 32P corre a 8 Mhz.
O RTX 32P foi desenhado para aplicações de controlo em tempo real, com especial destaque para ambientes de aplicações embutidas com exigências de baixo consumo e pequenas dimensões.
O PSC1000, desenvolvido pela Patriot Scientific, é uma das mais recentes máquinas de pilha [ver notícias]. É baseado na tecnologia ShBoom, patenteada pela empresa. A sua filosofia de concepção é a da simplicidade e eficiência.
A crescente popularidade do Java não foi alheia ao facto da Patriot Scientific apostar no Java como imagem de marca deste processador. Inicialmente desenvolvido para executar eficientemente programas em C e Forth, consegue executar código Java nativamente. O Java está desenhado para correr numa arquitectura orientada à pilha, portanto o PSC1000 é uma interessante plataforma.
Desenvolvido para aplicações Java e Internet, bem como os tradicionais mercados de aplicações embutidas, pretende ser um processador líder em nichos de mercado como as comunicações móveis.
Possui um formato de instruções de 0 operandos que reduz o tempo de descodificação e o espaço necessário para cada instrução. As instruções ocupam 8 bits, aumentando significativamente a largura de banda e diminuindo o tamanho dos programas. Não usa pipeline ou execução superescalar e, no entanto, normalmente completa uma instrução a cada ciclo de relógio, sem a necessidade de uma cache de instruções. Para assegurar o seu baixo custo, é eliminada a cache de dados em favor de caches de registos eficientes.
Ao usar opcodes de 8 bits, o processador pode obter até quatro instruções de cada vez que um instruction fetch é efectuado. Estas instruções podem ser repetidas sem a necessidade de as voltar a ler da memória, mantendo uma elevada performance quando directamente ligados à DRAM, sem a necessidade de cache.
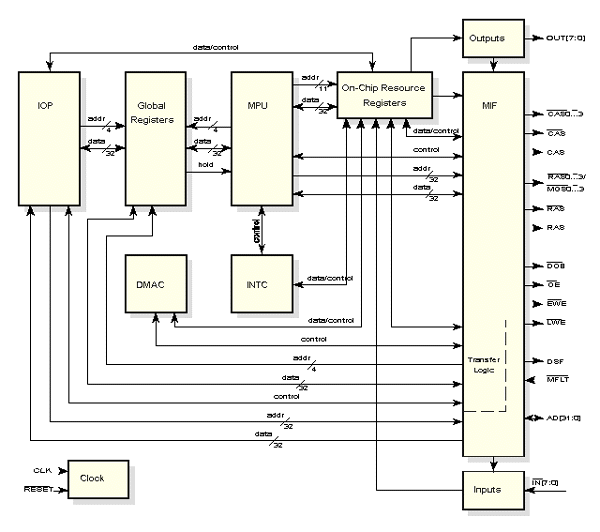
O PSC1000 é constituído pelas seguintes unidades funcionais:
Tem dois processadores: uma unidade de microprocessamento (MPU) de elevada performance, com duas pilhas e formato de instruções com 0 operandos e um processador de I/O (IOP) que executa instruções de transferência de dados, conta eventos, mede tempos e efectua outras operações de temporização.
A existência de registos locais e globais minimiza o número de acessos à memória de dados. A pilha de registos locais automaticamente guarda até 16 registos e a pilha de operandos até 18 registos, sendo o espaço eficientemente aproveitado entre chamadas a procedimentos. Os 16 registos globais proporcionam uma forma de armazenamento de dados partilhados.
O Direct Memory Access Controller (DMAC) permite que os dispositivos I/O transfiram dados de e para a memória sem a intervenção da MPU. Suporta até 8 canais I/O, por prioridades, de 8 fontes separadas. As prioridades dos pedidos podem ser fixas, o que permite que pedidos de maior prioridade bloqueiem pedidos de menor prioridade, ou giratórias permitindo que pedidos de maior prioridade que não podem ser satisfeitos não bloqueiem pedidos de menor prioridade.
O controlador de interrupções (INTC) permite que múltiplos pedidos internos ou externos obtenham a atenção da MPU, de uma forma ordenada e baseada em prioridades. Suporta até 8 pedidos de interrupção de 22 fontes.
Os on-chip resource registers compreendem partes das várias unidades funcionais do PSC1000. Estes registos são endereçados pela MPU ao nível dos registos ou ao nível dos bits. Ao usar um espaço de endereçamento separado para estes recursos o espaço normal de endereçamento mantêm-se inalterado e os opcodes são preservados.
Estão disponíveis 8 bit Inputs. Podem ser usados nos pedidos de interrupção, pedidos de acesso directo à memória, como input a instruções de I/O e como uso geral pela MPU.
Os 8 bit Outputs podem ser acedidos pelo IOP e pela MPU. São lidos e escritos pela MPU como um grupo ou individualmente. O IOP apenas pode escrever individualmente os bits.
O interface de memória programável (MIF) permite que a temporização e comportamento do bus de interface do processador seja adaptado às necessidades de dispositivos periféricos com uma lógica externa mínima. Um variedade de dispositivos de memória são suportados, incluindo EPROM, SRAM, DRAM e VRAM, bem como uma variedade de dispositivos de I/O. A maioria das características do bus de interface são programáveis, incluindo tempos de preparação e armazenamento de endereços, tempos de preparação e armazenamento de dados, tempos de disponibilidade e indisponibilidade do buffer de output, tempos do ciclo de memória, etc.
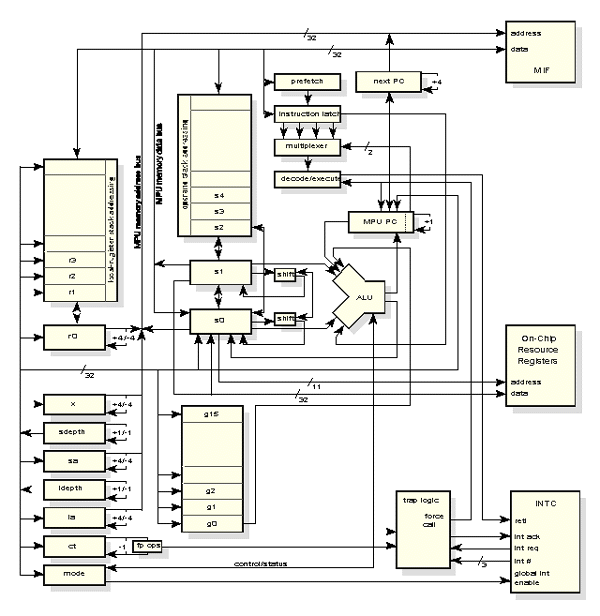
A ALU opera com os valores de topo da pilha de operandos, simplificando e reduzindo o bus de dados. Os resultados intermédios são colocados na pilha e acedidos directamente sem a necessidade de colocação e gestão de registos. As pilhas automaticamente fazem a gestão de overflow/underflow, eliminando a necessidade de gestão por software. Sempre que é necessário mais espaço de armazenamento a pilha de registos locais fornece registos que são eficientemente usados entre funções, uma vez que apenas é reservado espaço para os dados efectivamente armazenados ao contrário das arquitecturas que usam um tamanho fixo de janela de registos.
Apesar de cálculos em vírgula flutuante serem sempre necessários, e por vezes fundamentais, não são muito usados em aplicações embutidas. Em vez de consumir espaço no chip com uma unidade de vírgula flutuante, a MPU usa instruções que executam eficientemente as operações de vírgula flutuante, em precisão simples e dupla, usando o shifter para reduzir o número de ciclos necessários.
A pilha de operandos contém 18 posições, com acesso directo aos 3 elementos de topo. Operações aritméticas, lógicas, de movimentação de dados e processamento de resultados intermédios são realizados na pilha de operandos.
A pilha de registos locais contém 16 registos, com acesso directo aos primeiros 15 elementos. É usada para armazenar endereços de retorno de subrotinas e dados locais.
Ambas as pilhas colocam e retiram automaticamente valores da memória, quando necessário. Os elementos de topo destas pilhas podem ser usados para acesso à memória.
Os 16 registos globais são usados para armazenamento de dados, armazenamento de operandos nas operações de multiplicação e divisão da MPU e pelo IOP. Uma vez que estes registos são partilhados, a MPU e o IOP podem comunicar entre eles.
Existem ainda os registos mode, que contém informação de estado; o registo x que é um registo de indexação, em conjunto com os elementos de topo da pilha de operandos e de registos locais; e o registo ct que é um contador para ciclos e participa em operações de vírgula flutuante.
Todas as instruções da MPU são de 8 bits, excepto aquelas com dados associados. Isto permite que até quatro instruções sejam obtidas a cada instruction fecth, reduzindo a largura de banda necessária comparado com as máquinas RISC tradicionais de 32 bits. É também possível a existência de saltos num destes grupos de instruções (micro-salto) sem a necessidade de obter mais instruções da memória, aumentando significativamente a eficiência.
Opcodes de 8 bits podem não ser suficientes para determinadas instruções, como instruções de salto e instruções com valores imediatos. No entanto, instruções de tamanho variável complicam a descodificação das instruções. Para simplificar o problema, os valor dos literais é sempre obtido do byte mais à direita do grupo de instruções, independentemente da posição do opcode associado. Da mesma forma, os offsets das instruções de salto são sempre obtidos a partir dos bits à direita do opcode, independentemente da posição do opcode. Esta abordagem assegura que os dados estão sempre encostados à direita, simplificando e reduzindo o controlo necessário e acelerando a execução das instruções.
Instruções de salto
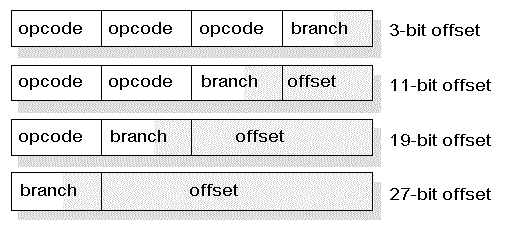
Literais
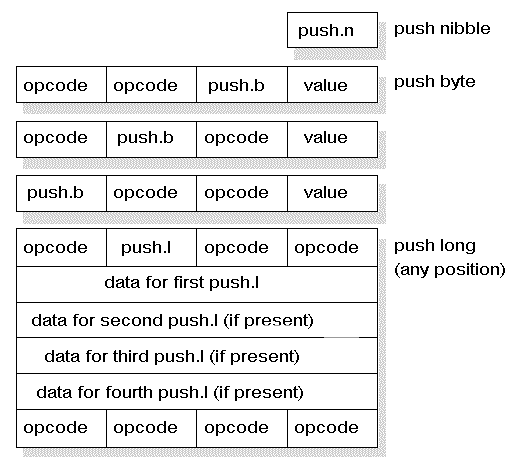
Restantes instruções

O PSC1000 é uma máquina de pilha com um formato de instruções com 0 operandos. Os operandos são sempre assumidos como sendo os elementos de topo da pilha de operandos. Uma operação de soma obtém ambos os operandos a partir do topo da pilha, adiciona-os e retorna o resultado para o elemento de topo da pilha de operandos, reduzindo uma posição à profundidade da pilha. A maioria das operações da ALU comporta-se desta forma, usando dois operandos e retornando um operando para a pilha de operandos. Um número reduzido das operações da ALU usa apenas um operando e retorna um valor para a pilha de operandos. Existem algumas operações que necessitam de um registo fora da pilha.
As operações de leitura e escrita na memória são semelhantes. Um load usa um endereço colocado na pilha de operandos ou especificado num registo e colocam o valor obtido na pilha de operandos. Um store usa um endereço colocado na pilha de operandos ou especificado num registo e usa os dados da pilha de operandos. As operações de movimentação de dados obtêm os dados de um registo e colocam-nos na pilha de operandos e vice-versa.
Quando os dados estão na pilha de operandos podem ser usados por qualquer instrução que obtenha os dados a partir da pilha. O resultado de uma instrução pode ser guardado indefinidamente até ser usado por outra instrução posterior. Existem instruções para reordenar os primeiros elementos de topo da pilha para que resultados anteriores possam ser acedidos quando necessário. Os dados também podem ser retirados da pilha de operandos e colocados na pilha de registos locais ou nos registos globais para minimizar ou eliminar uma posterior reordenação dos elementos da pilha.
Os registos globais são usados directamente e mantêm os seus dados indefinidamente. Como os registos locais são uma pilha o seu espaço tem de ser reservado antes de qualquer operação. Esta reserva de espaço pode ser feita elemento a elemento ou por blocos. Quando se reserva um bloco na pilha de registos locais, estes registos não estão inicializados. Para lhes atribuir um valor é necessário retirar um elemento de cada vez do topo da pilha de parâmetros e colocá-los na pilha de registos locais em qualquer ordem.
Os parâmetros são passados e retornados entre subrotinas através da pilha de operandos. Assim o número de parâmetros não está limitado ao número de registos como acontece nas máquinas baseadas em registos.
Os endereços de retorno das subrotinas são colocados na pilha de registos locais, aparecendo como o topo da pilha à entrada na subrotina, com o anterior topo da pilha visto agora como o segundo elemento e assim sucessivamente.
À medida que os dados são colocados nas pilhas e o espaço disponível de armazenamento se preenche, os valores são passados para a memória quando necessário. Da mesma forma, quando os dados são retirados da pilha e o espaço de armazenamento esvazia, os valores são lidos da memória e novamente colocados na pilha. Assim, do ponto de vista do programador, os elementos da pilha estão sempre disponíveis.
De entre os clássicos de 32 bits podemos encontrar os seguintes exemplos:
FRISC 3 - processador de 32 bits, hardwired, optimizado para executar programas em Forth. O nome FRISC vem de Forth Reduced Instruction Set Computer. O principal objectivo deste processador é a execução de primitivas Forth num único ciclo de relógio em ambientes de controlo em tempo real. Este processador foi usado em experiências com a Space Shuttle, no projecto JHU/APL HUT (Hopkins Ultraviolet Telescope) devido à necessidade de um processador que executasse rapidamente primitivas Forth em aplicações de controlo espacial.
SF1 - processador com 5 pilhas desenhado para executar eficientemente programas em Forth, C e outras linguagens de alto nível. Apesar de ter as suas raízes na linguagem Forth, permite que cada instrução enderece qualquer dos elementos de duas pilhas directamente a partir da memória da pilha. Permite, então, especificar dois operandos no conjunto de instruções, constituindo um interessante tema de estudo entre máquinas com 0 operandos e dois operandos suportados pelas instruções. Permite o acesso arbitrário aos elementos da pilha usando um endereço de 13 bits relativo ao elemento de topo.
![]()
![]()
![]()