This Developer's Guide describes the design and implementation of the Open Agent Architecture (OAA), and provides a description of how to create agents within this framework.
This document assumes a general familiarity with software engineering practices and programming language concepts. Some familiarity with the basics of the Prolog language is also helpful, as Prolog serves as the basis for OAA's Interagent Communication Language (ICL). Section 3.5, Notes on Terminology, provides some perspective on the terminology and notations that have been adopted from Prolog. For those wanting some background information on Prolog, a brief tutorial can be found at http://cbl.leeds.ac.uk/~tamsin/prologtutorial/, a longer tutorial is at http://www.intranet.csupomona.edu/~jrfisher/www/prolog_tutorial/contents.html and an online book is at http://cbl.leeds.ac.uk/~paul/prologbook/.
Sections 2 and 3 of this document give an overview of the design objectives and architectural features of the OAA. Section 4 explains the architectural elements of the OAA in greater detail, so as to provide the developer with a clearer understanding of how these elements fit together. Each of the remaining chapters focuses on one particular aspect of OAA agent programming, and presents detailed explanations of how to accomplish the most important and most common programming objectives.
For an exhaustive and detailed listing of library procedures, consult the OAA
Reference Manual.
The term "agent-based programming" has come to mean many things in today's technological jargon. Within the OAA framework, agents are seen as independent processes which communicate and cooperate with each other across a distributed network. We think of agents as more than just distributed objects because of their high-level communication language and their abilities to actively contribute to a computation as opposed to being only passive participants.
Although the goals and concepts for the Open Agent Architecture have been developed in detail elsewhere (OAA Specification Report, OAA Definition Report), it will be helpful to briefly restate some of the design objectives of the architecture here.
The OAA focuses on the idea of a community of agents working together to solve tasks for the user. Although it is possible in principle to create a single agent whose role is to autonomously accomplish all envisioned tasks, the benefits of the agent-based approach are best realized when computation is spread over many specialized "expert" agents. In the OAA framework, most requests from users are handled by the combined effort of multiple agents (for example, participating agents may include those that understand natural language input, plan actions, access databases, display results, etc.). This imposes a requirement that communication among agents be efficiently implemented, so as not to incur unacceptable overhead in executing a task.
The community of agents should be diverse, allowing agents to run on whatever platforms they choose, and to be written in any number of programming languages. The OAA provides a set of standard conventions which allows agents to work together under these conditions. In addition, distributed computation opens the door to parallel computation, where multiple agents may work either cooperatively or competitively on various aspects of a task.
As new members join the community, the overall effect of their interactions should change. If some agent joins the collaborative process as a latecomer, the interactions among agents must be flexible enough to allow the new agent to participate in computations. A "plug & play" architecture allows systems built with preexisting agents to easily take advantage of new functionality added later in the form of a new agent or agents.
Since human users are expected to be participants in the collaborative agent experience, the Interagent Communication Language (ICL), however defined, must be powerful enough to represent natural language (human) input. If the ICL can represent full natural language expressions, procedural (programmatic) interactions will also be possible.
Agents are more than just passive data sources that perform actions or return
information only when requested. Agents should be able to monitor actions in the
world around them and decide when to take action, perhaps alerting a user or
group of other agents about some pertinent situation. In addition, agents should
be able to watch the interactions of other agents, and perhaps make suggestions
about how to do something better.
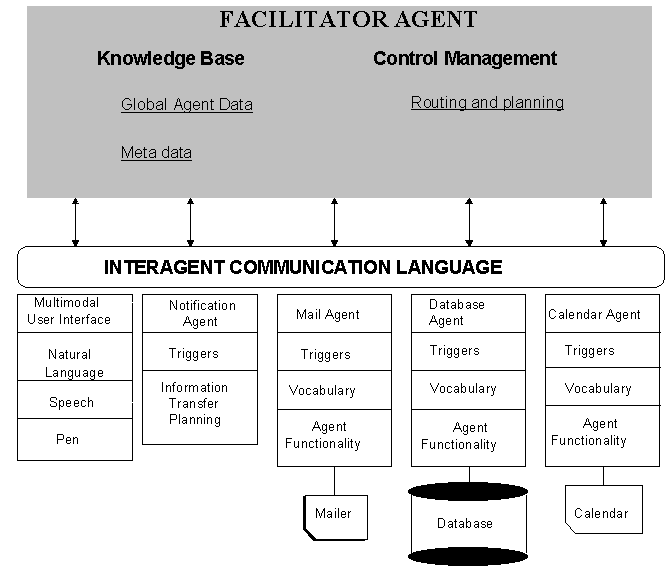
Figure 1 presents the basic structure of the Open Agent Architecture, using several agents from the Office Assistant prototype as examples of typical agents. The configuration shown in Figure 1 is composed of a multimodal user interface agent that analyzes input and coordinates the presentation of multimedia output to the user; a collection of domain agents for various office-related tasks; and a specialized server agent - the facilitator agent - that is responsible for coordinating agent communication and control. In many systems, the facilitator is also used to provide a global data store to its client agents. Note that a system configuration is not limited to a single facilitator; connectivity between multiple facilitators is discussed later in this document (see Using Multiple Facilitators).
Figure 1: OAA structure
Each agent in the OAA is either a facilitator agent or a client agent. Client agents are so called because each acts (in some respects) as a client of some facilitator, which provides communication and other essential services for the client. When invoked, a client agent makes a connection to a facilitator, which is known as its "parent facilitator". Upon connection, an agent informs its parent facilitator of the services it is capable of providing. When the agent is needed, the facilitator sends it a request using the Interagent Communication Language (ICL). The agent parses this request, processes it, and returns answers or status reports to the facilitator. In processing a request, the agent can make use of a variety of capabilities provided by the OAA. For example, it can request services of other agents, set triggers and read or write shared data on the facilitator (or other client agents that maintain shared data).
A facilitator maintains a knowledge base that records the capabilities of a collection of agents, and uses that knowledge to assist requesters and providers of services in making contact.
At the heart of the facilitator's functionality is a very general notion of transparent delegation. This means that a requesting agent can generate a request, and a facilitator can manage the satisfaction of that request, without the requester needing to have any knowledge of the identities or locations of the satisfying agents. At the same time, it is possible for a requesting agent to specify various forms of advice, or constraints, to guide the facilitator in handling its request. Transparent delegation is possible because agents' capabilities (solvables) are treated as an abstract description of a service, rather than as an entry point into a library or body of code.
A number of key declarations and other program elements are specified using ICL expressions. These include capabilities declarations, events (communications between agents), requests for services, responses to requests, trigger specifications, and shared data elements.
Additional details regarding the ICL appear in The Interagent Communication Language.
Because of the heterogeneity of implementation languages, platforms, and origins that is likely to be present among the agents of a system, there can be a fair amount of complexity involved in starting up a system, and in keeping in running. To alleviate some of the effort involved, the OAA includes an execution manager, Start-It.
Once a collection of interoperable agents has been assembled to work on a set of tasks, Start-It provides the means of invoking each of the agents on the correct platform, according to the system protocols of that platform, and ensuring that the agent makes the required connection to an OAA facilitator. Of equal importance, Start-It monitors the status of each agent to see that it continues to function correctly. In the event that Start-It detects a failure of one of the agents, it is able to take steps to recover from the failure and automatically restart the agent.
Startup specifications for each agent and instructions on how to deal with failures are contained in configuration files which can be automatically generated by a component of the Agent Development Tools. The use of Start-It is described in more detail below (see Section 11.1, Start-It).
One goal of the OAA is to facilitate the creation of agents using a wide variety of implementation languages. This Developer's Guide is intended for use by developers who are working with any of the languages currently supported. However, this creates a considerable challenge in selecting the appropriate terminology to use in referring to programming concepts.
The OAA has roots in Prolog programming, and some of the concepts of Prolog (in particular, unification and backtracking) are employed by the OAA. Consequently, the developer should have some understanding of these concepts, and these terms are used wherever appropriate in this Guide.
It is helpful to distinguish between general design concepts and implementation issues. In discussing design concepts, this manual employs general terminology that is clearly not related to any programming language. For example, we say that agents ``provide services'' that can be ``requested'' by other agents.
In discussing implementation issues, a careful mixture of Prolog-specific terminology and language-neutral terminology has been selected. In cases where Prolog terminology helps to characterize some OAA feature that is inherently Prolog-like, we use that terminology. For example, we say that an agent can ``solve a goal'' (or ``solve a query'') to emphasize first, that the goal must unify with one of the agent's capabilities specifications, and second, that the goal can have multiple solutions.
In a few other cases, we have adopted Prolog or logical notation simply because there is nothing language-neutral that is equally clear or convenient. For example, we use the notation foo/3 to refer to a procedure foo with 3 arguments, and we refer to foo itself as the functor of the procedure.
Otherwise, insofar as possible, we have tried to use terminology that is widely familiar and can be considered to be programming language-neutral. For example, instead of the Prolog term ``predicate'', we use ``procedure'' or ``declaration'', depending on context.
When describing library procedures, we sometimes characterize their arguments with the symbols '+', '-', and '*', as in this example:
oaa_Solve(+Goal, +Params, -Solutions)The '+' means that the corresponding argument is an input argument (bound to some value at the time of calling the procedure), the '-' means it is an output argument (not bound when calling, but expected to be bound when the procedure returns), and the '*' means the argument can be used for either input or output.
The agent library provides functionality that is common to all agents in the OAA, including facilitator agents; in a sense, the capabilities provided by the agent library determine what it means to be an OAA agent. The library has been ported to a number of different programming languages, and the inclusion of the library is part of the implementation of every agent. The agent developer needs to call procedures provided by the library, and needs to provide certain declarations and define certain callback procedures that are expected by the library. These procedures and declarations are described throughout this Developer's Guide. This section, on Agent Infrastructure, describes some basic features of the agent library, and some uses of the library that are common to all agents.
To date, all OAA-based systems have employed TCP/IP (Transmission Control Protocol / Internet Packets) as transport protocol. TCP is standardized on many operating systems (UNIX, Macintosh, DOS, Microsoft Windows, and so forth), so its use facilitates the task of interoperating agents on a wide variety of platforms.
It should be noted, however, that OAA has been structured so as to allow the use of a variety of transport protocols. This has been done by specifying an API for the transport layer. The transport layer is handled as a distinct module, and loaded separately from the remainder of the library procedures. Procedures in the transport layer are named using the prefix com_. All communications between agents go through this API. In no case does the developer need to be concerned with any of the details of TCP/IP, or any other transport protocol.
With the exception of com_Connect, the agent developer does not normally need to call procedures in the transport layer. Calls to these procedures are usually made by higher-level procedures, such as oaa_Solve.
For those familiar with speech-act-based agent frameworks such as FIPA or KQML, the ICL includes a layer of conversational protocol, similar in spirit to that provided by KQML, and a content layer, analagous to that provided by KIF. The basis of the ICL in logic programming allows for a consistent integration of these two layers, while at the same time providing considerable flexibility in how they are used.
The conversational layer of the ICL is defined by the event types, together with the parameter lists that are associated with certain of these event types. The content layer consists of the specific goals, triggers, and data elements that may be embedded within various events.
While it is possible to embed content that is expressed in other languages within an ICL event, it is advantageous to express content in the ICL wherever possible. The primary reason for this is to allow the facilitator access to the content, as well as the conversational layer, in delegating requests. Not only does this give the facilitator more information about the nature of a request, but it also makes it possible for the facilitator to decompose compound requests, and delegate the subrequests individually.
In the following sections, we briefly explain how the ICL is used in each of its different roles.
One aspect of a solvable that is worth mentioning up front is its type, which may be either procedure, data, or trigger. Procedure and data solvables declare capabilities that may be used directly by other agents. (Normally, other agents use these solvables by calling the library procedure oaa_Solve.)
Conceptually, a procedure solvable accomplishes an action, whereas a data solvable stores a set of facts (just as a database relation does). For example, in creating an agent for a mail system, procedure solvables might be defined for sending a message to a person, listing messages that have arrived about a particular subject, or displaying a particular message onscreen. For a database wrapper agent, one might define a distinct data solvable corresponding to each of the relations present in the database. Often a data solvable is used to provide a shared data store, which may be not only queried, but also updated, by a number of agents having the required permissions.
Although many of the OAA library procedures for requesting services apply to both procedure and data solvables, there are also a number of library procedures that are exclusively for use with data solvables, as explained in Section 7, Maintaining Data.
Trigger solvables are not directly accessible by other agents. Rather, other agents use trigger solvables indirectly, by setting task triggers on them (as explained in in Section 8, Using Triggers). A trigger solvable exists just for the purpose of explicitly declaring task-specific conditions or events, on which the agent is able and willing to allow triggers to be set. For example, an email agent might declare a trigger solvable that checks for the arrival of a message for some person, about some subject. This tells other agents (and the facilitator) that triggers can be installed on the agent, which fire when a condition of that form is satisfied.
Note that there are several types of triggers, of which task is only one. However, task is the only trigger type that requires the declaration of trigger solvables. An agent declares its solvables by calling library procedures such as oaa_Declare and oaa_Undeclare.
These procedures, and the precise form of the solvable, are given in section 5, Providing Services.
For example, a call to
oaa_Solve(Goal, Params)within some agent A, results in an event having the form
ev_solve(GoalId, Goal, Params)going from A to the facilitator, and a return message having the form
ev_solved(GoalId, Requestees, Solvers, Goal, Params, Solutions).(In addition, between the occurrence of these two messages, there are other messages between the facilitator and the solver(s) of the request.)
Because events are normally constructed and transmitted transparently, the developer of an agent is not generally concerned with their details, except for those events that correspond to requests for the services provided specifically by that agent.
The OAA libraries provide an agent with a single, unified point of entry for requesting services of other agents: the library procedure oaa_Solve. In the style of logic programming, oaa_Solve may be used both to retrieve data and to initiate actions. To put this another way, calling a data solvable looks the same as calling a procedure solvable.
oaa_Solve provides a number of different parameters that may be used to modify the behavior of the facilitator and/or other agents in performing the requested service. In particular, it is the address parameter that allows for the explicit delegation of a call to one or more agents. It is also possible for an agent to use oaa_Solve "locally"; that is, as a convenient and consistent means of accessing the agent's own capabilities. This is done by giving the calling agent's own address as the value of the address parameter.
Section 6, Requesting Services, provides full details on the use of oaa_Solve.
OAA triggers provide a general mechanism by which an agent can specify an action to be taken when some set of conditions is met. Each agent can install triggers either locally, on itself, or remotely, on its facilitator or a peer agent. Triggers fall into four categories: communication, data, task, and time triggers.
Triggers are related to solvables in two ways. First, all triggers are implemented as data solvables, declared implicitly for every agent. That is, when a trigger is installed on an agent, the agent library records the trigger as an instance of a built-in data solvable, oaa_trigger/5. This makes it possible for an agent to query currently installed triggers, using oaa_Solve, just as it would query any other data solvable.
Second, task triggers require the declaration of a trigger solvable, as explained in Declarations of Capabilities (Solvables).
The use of triggers is described in Section 8, Using Triggers.
[type(data), single_value(true), persistent(true)]As illustrated by this example, all parameters are specified using a functor (such as type), and one or more arguments. Most, but not all, take only a single argument. Most, but not all, are boolean, where the argument's value is either true or false.
Many parameters have a default value; for example, the default value of parameter type/1 is procedure. When you want a parameter to have its default value, it is not necessary to specify the parameter at all. In fact, when you call a library procedure, such as oaa_Solve, and your parameter list includes default values, these are normally removed before the request goes to the facilitator, to conserve bandwidth. However, there is certainly no harm in specifying default values, and at times you may wish to do so to produce more readable code.
A boolean parameter with value true can omit the value specification. For example, the parameter list above could also be written as:
[type(data), single_value, persistent]
To retrieve a parameter's value from a parameter list, call the library procedure icl_GetParamValue. For example, in Prolog, given a parameter list Params, you can retrieve the value of the from parameter in this fashion:
icl_GetParamValue(from(Requestor), Params)
The relevant parameters in each context, and their meanings and default values, are described in the appropriate sections of this manual and the reference manual.
An agent may have one or more open server connections ("listener" sockets in TCP), and one or more open client connections. Normally, the facilitator maintains a single server connection, and each client agent maintains a single client connection to its facilitator (which is obtained by calling com_Connect, followed by oaa_Register).
Every agent (including facilitators) has a symbolic name, a full address, and a local address (or "local ID"), for each open client connection and each open server connection. The form of the full address is dependent on the communications protocol in use. For example, assuming the use of TCP/IP, a facilitator's address will appear as
addr( tcp(Host, Port) ),and the address of a client agent will appear as
addr( tcp(Host, Port), LocalID).
Even though it doesn't appear in the full address, a facilitator also has a local ID, for consistency -- but this isn't normally used by a client agent. The local ID of a client agent is assigned to it by its facilitator, which passes the client's full address to the client at connection time (that is, during the execution of the client's call to oaa_Register).
Since a facilitator must have exactly 1 (server) connection with connection id 'fac_listener', and a client (non-facilitator) must have exactly 1 (client) connection with connection ID 'parent' (although they may have other connections with other connection ids), we have the notion of a "primary address". The primary address for a facilitator is the full address for its fac_listener connection, and for a client is the full address for its parent connection.
After a client agent has registered with its facilitator, it can obtain its full address by calling
oaa_PrimaryAddress(MyAddress)and the full address of its facilitator can be obtained by calling
oaa_Address(parent, _, ParentAddr)
Full addresses are globally unique, and local addresses are unique with respect to a facilitator. Symbolic names are not unique in any sense. The local ID happens to be an integer in the current implementation, but developers should not rely on this.
When specifying addresses, in address/1 parameters for calls to oaa_AddData, oaa_Solve, etc., either names or addresses may be used. In addition, for convenience, reserved terms self, parent, and facilitator may also be used.
More precisely, the value of an address parameter can be one of the following, or a list containing any number of the following:
When calling oaa_AddData, oaa_Solve, etc., address parameters are standardized as follows: local IDs are changed to full addresses, relative to the 'fac_listener' connection (for a root or node agent), or to the 'parent' connection (for a leaf). Full addresses are left as is. Names are left as is, but ensuring they're enclosed within name/1. 'self', 'parent', and 'facilitator' are changed to the appropriate full address.
The addresses of an agent's peer agents can be obtained by calling the facilitator solvable can_solve. For example, to find the address of a peer agent that can solve Goal, an agent would ask for solutions to can_solve from its parent facilitator:
oaa_Solve(can_solve(Goal, AgentAddress), [address(parent)])
which returns addresses for agents whose solvable list matches the desired
Goal. There are also several other means of obtaining addresses of other agents:
by calling the facilitator's solvable agent_data/6; by retrieving the
value of the from/1 parameter to a callback
procedure; or by the use of the get_address/1 and
get_satisfiers/1 parameters, which may be used with a number of different
library procedures.
oaa_RegisterCallback(app_idle, ProcedureName)Library code calls this procedure, if registered, with no arguments. (Note: the app_idle callback is not used in the Java library.)
oaa_RegisterCallback(app_done, ProcedureName)When an agent is quitting, library code calls this procedure, if registered, with no arguments.
oaa_RegisterCallback(app_setup_trigger, ProcedureName)When a task trigger is installed, library code calls this procedure with 4 arguments: Type, Condition, Action, Params. These arguments are the same as those passed to oaa_AddTrigger, by the agent requesting the trigger installation.
fac -oaa_connect "tcp('mymachine.ai.sri.com', 3345)" ...
tcp('mymachine.ai.sri.com', 3345)
oaa_connect( tcp('mymachine.ai.sri.com', 3345)).
(Note, however, that oaa_connect should be used with care in a
setup file. Another alternative, default_facilitator,
works better for most situations.) When creating new invocation arguments for specific client agents, developers are encouraged to follow these same conventions. Library procedure oaa_ResolveVariables may be used to search the command line, environment, and setup file.
The agent library contains code that loads a setup file if it is present in any of the following locations:
A setup file is loaded when library procedure oaa_ResolveVariables is called for the first time, with setup/3 specified in its argument list.
default_facilitator(tcp(HostName, PortNumber)).
oaa_AddData(Clause,[address(self)])for each data predicate declared.
For this reason, when it is desired to specify a connection address in a setup file, it is usually best to use
default_facilitator(tcp(HostName, PortNumber)).which specifies the OAA address at which a facilitator agent may be found. This predicate will be used by a client agent to find a Facilitator agent to connect to, and if read by a Facilitator agent, will be interpreted as the communication address at which it should listen. Currently, tcp is the only communication protocol used with OAA agents. In this case, PortNumber is expressed as an integer, and HostName as a Prolog atom, as in the following example:
default_facilitator(tcp('acapulco.ai.sri.com', 3333)).
Note that when Facilitator agents are arranged hierarchically in a multi-facilitator topology, the use of default_facilitator in a setup file is not appropriate, unless it is known that each facilitator will read a different setup file, or will get its address information from the command line or environment.
Although connection addresses are usually fully specified for a Facilitator
agent, it is possible to specify a variable for either the host or port. In this
case, acceptable values will be automatically chosen by the system.
solvable(GoalTemplate, Parameters, Permissions)Any permissions or parameters taking a default value (see Parameter Lists) may be omitted, so it is often the case that a solvable's permissions and/or parameters are just the empty list. (In these cases, several shorthand forms allow for briefer and more readable solvables.)
For example, the solvable list for a simple mail agent might look like this:
[solvable(send(mail, ToPerson, Msg), [callback(send_mail)], []),
solvable(last_message(MessageNum),
[type(data), single_value(true)],
[write(true)]),
solvable(get_message(MessageNum, Msg), [callback(get_mail)], [])
]).
This simple agent offers three solvables. The first, a procedure
solvable (by default), results in sending an email message to the person
indicated in the second argument, ToPerson. The second, a data
solvable, provides the numeric index of the last message received. The third, a
procedure solvable, when given a numeric index, returns the message
associated with that index.
For those readers with limited knowledge of Prolog, we note that ToPerson, MessageNum, and Msg are variables, whereas the other argument values (mail, data, true and false) are constants.
In the case of the goal template send/3, the variable ToPerson is expected to be bound when the solvable is called, whereas in the goal template last_message/1, MessageNum provides a return value; that is, free when the solvable is called, and bound when the solvable returns. This distinction is not apparent from the solvable specifications, however; it is only known by considering the meaning and context, or by reading the comments for the solvables.
The goal template of a solvable provides, at a conceptual level, a description of the service (or data) provided; at a functional level, a specification that the agent's facilitator can use in making delegation decisions; and at the level of communications, a template for the event which the agent will receive when the service is requested.
When writing a solvable goal template, it is important to understand that each goal template specification will be used according to the semantics of unification, just as it is used in logic programming. When the facilitator receives a request to solve some goal, it uses unification to test that request against the goal templates contained in the solvables specifications of its connected agents. (Solvables permissions and parameters do not figure in the unification, only goal templates.) By default, each connected agent for which the unification succeeds receives the request. The event that expresses this request, as sent to the agent by the facilitator, and passed to the agent's callback procedure, is the result of this unification.
A solvable's permission list may contain the following boolean permissions. In each case, the meaning of the permission applies to all agents ( including the one declaring the solvable). Although this may be considered counterintuitive in some respects, improvements have been deferred until a more comprehensive permissions scheme is developed.
In the example solvable list above, the first and third solvables need not specify any permissions, because they use only the default values, which are call(true), write(false), read(false). The second solvable, last_message, specifies the non-default permission write(true), to allow updates to the data associated with this solvable. It is very common to use write(true) with data solvables. A solvable's permissions can be modified at anytime.
There are a number of parameters that may be used to characterize a solvable. Of these, the most important are type/1, utility/1, and callback/1.
The value of type/1 can be either data, procedure, or trigger; the default is procedure. These three types are informally characterized in Section 4.3.1, Declarations of Capabilities (Solvables).
As explained there, procedure and data solvables can both be accessed by calling oaa_Solve. Technically, there are three specific differences between these two types of solvables. First, a data solvable can be updated using library procedures oaa_AddData, oaa_RemoveData, and oaa_ReplaceData. Second, it is not necessary (or possible) to define a callback procedure for a data solvable. Finally, for a data solvable, the agent library maintains a record of which facts are created by which agents, and uses this information to remove an agent's facts when the agent goes offline. (This behavior can be modified using solvable parameters bookkeeping/1 and persistent/1.)
The value of utility/1 can be any integer between 0 and 10; the default is 5. This parameter provides a means of giving a qualitative indication of how well the agent performs the service implemented by the solvable, with larger numbers expressing higher quality of service. This number is used by the agent's facilitator, when multiple agents offer the same solvable. When a facilitator receives a request for such a solvable, it orders the available solvers by decreasing utility, which means the agents claiming higher utility will receive the request first. Or, if the request is accompanied by certain combinations of parameters (see the strategy(action) parameter to oaa_Solve), the agent claiming the highest utility may be the only one to handle the request.
The value of callback/1 is an ICL expression that names a user-defined procedure. The use of this procedure is described below, in Defining Request Handlers.
An exhaustive list of solvables parameters, with their possible values and default values, is given in the Reference Manual. General characteristics of parameter lists are explained in Section 4.3.6, Parameter Lists.
Specifications of solvables have a standard form and several alternative shorthand forms. The shorthand forms are provided primarily for backwards compatibility with earlier versions of the agent library. Each library procedure that takes a solvable list as an argument will accept any of these forms, so that developers' calls to these procedures may be made more readable, in some situations. In addition, it is always acceptable to pass in a single solvable, instead of a list. When the solvable or solvable list is passed in using one of the shorthand forms, it is converted to standard form. Thus, when debugging their code, developers may see the results of this conversion.
The differences between standard and shorthand forms are straightforward. In standard form, each solvable term contains all three arguments:
solvable(GoalTemplate, Parameters, Permissions)and default values are omitted from Permissions and Parameters. Shorthand forms are obtained simply by omitting the second and/or third arguments. That is, if Permissions is the empty list, it may be omitted. If both Permissions and Parameters are empty (this can only happen with a procedure solvable, using the default callback), they may both be omitted. In this case, it is also acceptable to omit the solvable functor. For example, this solvable list:
[solvable(get_message(MessageNum, Msg), [], [])]could be passed to a library procedure in any of the following forms:
[solvable(get_message(MessageNum, Msg), [], [])]
[solvable(get_message(MessageNum, Msg), [])]
[solvable(get_message(MessageNum, Msg))]
solvable(get_message(MessageNum, Msg), [], [])
solvable(get_message(MessageNum, Msg), [])
solvable(get_message(MessageNum, Msg))
get_message(MessageNum, Msg)
A call to oaa_Register is the means by which a client (that is, non-facilitator) agent normally registers with a facilitator, and informs the facilitator of its solvables. oaa_Register should be called after opening a communications channel to the facilitator, using com_Connect. Every client agent is required to connect and register with a facilitator to participate in a community of agents. However, it is not required that the agent specify its solvables when it registers. If an agent wishes to specify its solvables later, it may do so using oaa_Declare.
If an agent has no solvables to declare when it connects, it may pass the empty list ([]) as the third argument to oaa_Register.
The AgentName argument is the symbolic name by which the client agent will be known to its facilitator and other agents (see Agent Names and Addresses).
A call to oaa_Declare may be used at anytime after connecting to a facilitator. Each solvable in Solvables is added to the agent's list of current solvables, both locally and in the agent's facilitator (unless private(true) appears as a parameter, in which case the facilitator does not learn of it).
A call to oaa_Undeclare results in the removal of each previously declared solvable that is listed in Solvables.
This library procedure may be used to simultaneously remove one solvable, and install another. Conceptually this is the same as a call to oaa_Undeclare followed by a call to oaa_Declare, with the appropriate arguments, except that oaa_Redeclare ensures the two operations take place at the same time. This is especially useful when changing the permissions or parameters associated with an existing solvable.
In addition to declaring solvables for itself, an agent can ask its facilitator to declare solvables of type data; this is done by including address(parent) in the Params argument. When this is done, the result is a shared data predicate that can be read and written by all clients of the facilitator. This is one way of implementing a "blackboard" approach to communication and coordination between agents.
When an agent receives a request for one of its services declared as a procedure solvable, the callback procedure for that service is called. To handle these calls, each agent must define code that implements the callback procedure of each solvable it has declared of type procedure. (Callbacks for data solvables are provided transparently by the agent library, and trigger solvables have no need of callbacks.)
As explained in the preceding section, a callback procedure for a solvable can be specified in the parameter list of the solvable's declaration. It is also possible to declare a default app_do_event callback for procedure solvables, using oaa_RegisterCallback. When this is done, any request for a procedure solvable, which has no specified callback, will go to the default callback.
In Prolog, callback procedures, are assumed to be defined in module user, unless some other module is explicitly indicated. This may be done using the standard syntax Module:CallBack; for example, callback(my_module:my_procedure).
The callback procedure is always called with two arguments: the incoming goal to solve, and a parameter list. The return value(s) of the callback procedure are the instantiated solutions to the goal. In Prolog, these are returned by the usual means, using backtracking to provide various bindings of the goal's variables.
For example, for the solvables declared above, in a Prolog implementation, the callbacks would be defined as follows:
send_mail(send(mail, ToPerson, Msg), Params) :-
<code implementing the send solvable ...>
get_mail(get_message(MessageNum, Msg), Params) :-
<code implementing the get_message solvable ...>
Either or both of these solvables could have had their goals handled by the default app_do_event callback, if one has been declared. Regardless of whether you choose to use a default callback for any (or all) of your solvables, it is sometimes necessary to define a default callback for handling some events other than those associated with solvables. For instance, Section 6.8 describes how it may be used to intercept ev_solved/6 events returned asynchronously from other agents.
Notice that there is no callback defined for the last_message solvable, because it is a data solvable.
In general, when defining a callback procedure, the parameter list argument may be ignored; that is, the goal argument contains the essential information for satisfying the incoming request. However, occasionally it may be useful to know what agent has made this particular request. This may be determined by retrieving the value of the from parameter; for example, in Prolog:
send_mail(send(mail, ToPerson, Msg), Params) :-
icl_GetParamValue(from(Requestor), Params),
....
In the agent libraries for languages such as C, Delphi or Visual Basic, because those languages do not provide backtracking, the conventions for returning multiple solutions from a callback procedure are slightly different than for Prolog.
In the C, Visual Basic and Delphi libraries, the callback procedure returns success, failure or multiple solutions to the incoming request in the variable answers. For an event request send(mail,'Adam', Msg), a successful action would return "[send(mail,'Adam', Msg)]" in answers, and failure would be indicated by returning the empty solution list "[]". Multiple solutions can be returned as well: the query manager(adam,X) could return two solutions by storing "[manager(adam,jerry),manager(adam,doug)]" in answers.
Normally, a callback procedure responding to a request from the agent community does all of its work and assembles all its solutions before returning.
There is also the possibility of delaying the return of a callback procedure's solutions until some future time. This is often useful for events which may take a long time to complete, or will depend on information or events that arrive asynchronously. For example, if a robot has been asked to attain a certain position, this is not a goal that can be achieved quickly. In such cases, it may be desirable to return immediately from the callback procedure, so that other processing steps can proceed.
The process of delaying solutions in an app_do_event callback is handled in three steps:
Here is an example in Prolog, where an agent managing the control of robot movements publishes a solvable move_robot(RobotId,PosX,PosY). Since robotic movement can take a long time, and since event updates as to the robot's position and status arrive asynchronously over time, delayed solutions are used to implement the solvable.
% If someone asks me to make a robot move to (X,Y),
% I will tell the robot to start moving, but won't
% have completed the task until I know if the robot
% has reached the goal or has given up.
oaa_AppDoEvent(move_robot(RobotId, X,Y),_Params) :-
start_moving(RobotId, X,Y).
oaa_DelaySolution(RobotId).
% As the robot moves, we receive updates on its position,
% which we broadcast to all interested agents.
oaa_AppDoEvent(current_position(RobotId, X,Y),_Params) :-
% instead of calling oaa_Solve(robot_pos(RobotId,X,Y),[broadcast]),
% we break it into 2 steps to allow oaa_AddDelayedContextParams()
% to mix in any context parameters.
oaa_AddDelayedContextParams(RobotId, [broadcast], ParamsWithContext),
oaa_Solve(robot_pos(RobotId,X,Y), ParamsWithContext).
% We receive the event that say the robot has completed its task
% so we return solutions to the original request.
oaa_AppDoEvent(finished_moving_to(RobotId, X,Y),_Params) :-
oaa_ReturnDelayedSolutions(RobotId, [move_robot(RobotId, X, Y)]).
% Here we are notified the robot can't do the task and has
% given up, so we return failure (the empty solution list)
oaa_AppDoEvent(cant_move_to(RobotId, X,Y),_Params) :-
oaa_ReturnDelayedSolutions(RobotId, []).
Even though internally the treatment of the solvable move_robot() is handled in a delayed, asynchronous way, this is transparent to a requesting agent, who can issue a oaa_Solve(move_robot(robot1, 100,100),[]) request which will block until the robot has succeeded or failed in its goal.
The priority(P) parameter may be specified in two places:
Imagine declaring a solvable for your agent a(X), which relies on some information provided by the agent community, a1(X). When an incoming request arrives at your agent, the callback associated with a(X) is called as described above. This callback calls oaa_Solve(a1(X),[]), which blocks, waiting for solutions to be returned from the agent community. While the agent is waiting for solutions to be returned, new events may arrive on the communication channel. What happens to these new events? The following behavior is produced:
Meta-agents are simply OAA agents that define a special solvable or capability called "meta", in the form:
Note: other meta hooks may be added in the future.
Several meta-agent hooks may fire for the same query. For instance, if an agent performs oaa_Solve(a(X),[strategy(action)]) and no agent is currently loaded that can handle a(X), a "lookup" meta-agent may fire, loading several agents that can perform a(X). These agents will be prioritized in order of expected utility, and this sequencing may be then improved upon by "prioritize" meta-agent.
What happens if several meta-agents have differing opinions about how a goal should be handled? In this case, the Facilitator uses the "action" strategy to handle them: all meta-agents that can contributed are collected and themselves ordered according to expected utility. The first meta-agent is consulted, and if it returns useful information, the Facilitator uses it. If not, the next meta-agent in the list is consulted until at most one agent succeeds in providing information the Facilitator can use. If no information is found, the Facilitator proceeds with its default handling of the delegated task.
While performing a task, an agent can often make use of information and services provided by other agents. The mechanism for making requests of other agents is encapsulated in a single procedure, oaa_Solve/2. The oaa_Solve/2 procedure provides considerable flexibility in making requests, by selecting different combinations of parameter values. Here, we describe some of the more commonly used parameters. For a complete list, see the Reference Manual.
The standard way (in Prolog) to request a solution to some query is to call the procedure
oaa_Solve(Goal, ParameterList).
Note: Other programming languages such as C or Delphi have their own syntactic variants for all of the library routines described in this developer's guide. For instance, in C, the solve procedure is declared as
oaa_Solve(char *Goal, char *ParameterList, char **answers)
By default (that is, with an empty ParameterList ([]), or by calling the oaa_Solve/1 procedure which assumes an empty Parameter list), a call to this procedure directs the agent's facilitator to assemble all available solutions to Goal; that is, solutions from all of the agent's peers that offer Goal as a solvable. (Note that this description applies when Goal is non-compound; things are slightly more involved with compound goals.) From the programmer's point of view, however, it is used just as if Goal were being executed locally by a Prolog interpreter: it can fail or succeed, and multiple solutions can be obtained through backtracking. This is a very convenient and natural method of writing code when creating an agent's functionality.
When a goal is sent to a facilitator through a solve request, the facilitator looks for agents that can provide a response to the goal by matching the goal against the procedure and data solvables of all connected agents. If multiple agents have indicated that they can return solutions to the goal in question, the default behavior used by the facilitator is to send the request to all pertinent agents and to wait until all agents have responded, collecting the solutions from each agent and routing the set of all solutions back to the requesting agent. If you wish to override this default behavior, perhaps having individual agents send their specific solutions back to the requesting agent separately, use the reply parameter.
However, this default use of the solve procedure, while providing all of the power and expressiveness of Prolog, also has its shortcomings; for example, execution of the agent calling oaa_Solve is suspended until the goal has been solved, either succeeding or failing. This goal may take a certain time to resolve, as it will be posted to the facilitator, and then routed to another agent on another machine for processing. And during this time, the agent posting the query is dormant, waiting for the solution to return. There are, however, a number of alternative methods of posting queries, using the ParameterList, as explained below.
In some particular cases, an agent may decide to use oaa_Solve/2 with the cache parameter; that is,
oaa_Solve(Goal, [cache]).This behaves just like oaa_Solve(Goal, []), except that once the goal is computed, the solution is stored locally in the agent's database. The next time that the same goal is recomputed, the answer is found immediately, without accessing a remote agent. This optimization must be used with care, as the agent is responsible for maintaining the coherency of his own cache: if a solution is subject to changes over time, it is safer to omit the cache parameter.
The cache option should correctly handle subsumption. Imagine that a user first issues the request
oaa_Solve(hotel('fairmont', Info), [cache])
which returns one solution, storing this in the cache. If at a later
time, the user asks the query oaa_Solve(hotel(Any,Info),[cache])it would be an error to return only the solution stored in the cache; rather, the system must recognize that the cache does not have information stored which subsumes this query, so a new query must be posted over the network. Subsumption is currently correctly handled by the Prolog agent library, but is not correctly handled by the agent libraries in other programming languages.
An agent can choose to clear its own cache by using the primitive oaa_ClearCache.
As mentioned above, the default use of oaa_Solve/2, oaa_Solve(Goal, []), causes the responding agent(s) to generate all possible solutions to Goal. In some cases, depending on how the called procedure is written, finding multiple solutions may have undesirable side-effects. Thus, if the calling program knows that it needs only a single solution, or a limited number of solutions, it can prevent the responding program from finding all possible solutions, by using the solution_limit(N) parameter:
oaa_Solve(Goal, [solution_limit(N)])where N can be any positive integer.
This parameters tells each responding agent to find at most N solutions. In the presence of parameter parallel_ok(false), a solution limit can also influence the facilitator's behavior. For example, suppose that both solution_limit(10) and parallel_ok(false) have been specified for some request, and that the facilitator identifies 4 candidate solvers. If, say, the first two solvers return a total of 12 solutions, the facilitator will not send this request to either of the remaining two candidates.
When a request is received by a facilitator from some agent, the facilitator's normal behavior is to solicit solutions from all agents that claim to handle that sort of request, including for the requesting agent itself. If it is not desired that the requesting agent be included as a solver of a request, that may be indicated using the reflexive parameter:
oaa_Solve(Goal, [reflexive(false)])Even with the reflexive parameter true, the requesting agent will only be asked to solve a goal when the goal matches one of its procedure or data solvables.
In general, when requesting the solution to a goal, an agent posts the request to the facilitator without knowing which remote agent (or agents) will solve the goal -- the facilitator is responsible for transparently locating an appropriate agent (or agents). However, if the address(es) of a specific agent (or agents) are known, the address(es) can be indicated in the parameter list as
oaa_Solve(Goal, [address(AgentAddress)])Addresses are described in Agent Names and Addresses.
oaa_Solve(airline_rating(A, R), [owner(6)])will retrieve all facts of the data solvable airline_rating/2, which are owned by the agent with local ID 7.
Data ownership is explained in Section 7.5, Ownership of Data Elements.
OAA provides several options for controlling whether, and when, solutions are returned for a goal submitted to oaa_Solve; these are indicated using the blocking/1 and reply/1 parameters. blocking/1 controls the behavior of the requesting agent (the agent calling oaa_Solve), whereas reply/1 controls the behavior of the facilitator and the agents responding to the request.
The blocking/1 parameter is boolean:
The reply/1 parameter at present also has two possible values, but it is expected that there may be additional possibilities introduced in the future.
As explained in the previous subsection, the parameter blocking(false) may be used to request information from remote agents in a non-blocking fashion:
oaa_Solve(Goal, [blocking(false)])In this way, an agent's computation can continue while the request is being resolved. This is more efficient for the local agent; however it is slightly more difficult to program, because additional code is needed to handle the results of the request when they arrive.
Assuming the parameter reply(none) is not present, the results of a non-blocking query will generate an event of the form
ev_solved(GoalId, Requestees, Solvers, Goal, Params, SolutionList).The Requestees argument will be a list of the local ID(s) all agents asked to handle the request, and Solvers will be a list off the local ID(s) of the agent(s) that succeeded in handling it. Goal is a copy of the original goal submitted to oaa_Solve. Params is a copy of the original parameters submitted to oaa_Solve, except that any variables appearing in partially instantiated parameters will have been bound. SolutionList is a list of the goal's solutions, each of which is unifiable with Goal.
One way of handling the results of a non-blocking query is to provide a handler for the ev_solved/5 event, by declaring and defining an app_do_event callback. Another way is to trap the event by a local communication trigger, which supplies an action to be executed when the solutions are received.
The following example posts the query to be solved, and then sets up a trigger to display the results of the goal asynchronously when they are returned. While the goal is being executed remotely, the agent can perform other actions.
interface :-
get_query_from_user(PostableQuery),
oaa_Solve(PostableQuery, [blocking(false)]),
oaa_AddTrigger(comm,
ev_solved(_GoalId, _Requestees, _Solvers, PostableQuery, _Params, Solutions),
display(Solutions),
[address(self), recurrence(when), on(receive)] ).
Triggers are explained in Section 8, Using
Triggers.
Using the test parameter, you can specify a test to be executed on a local facilitator, and if the test succeeds locally, only then will the goal be solved on that facilitator. This is useful, for example, when specifying a goal such as "send a message to the interface agent, but only on a facilitator where the user's name is 'phil'" :
oaa_Solve(ui_inform('message'), [test(name('phil'))])
Note: the test parameter is useful primarily when multiple facilitators are used, as described in Section 10.1, Using Multiple Facilitators.
When agents are arranged in a hierarchy of multiple facilitators (see Using Multiple Facilitators), it is often important to indicate whether and to what extent a request should be propagated to remote facilitators. For this purpose, the propagate parameter may be used.
The propagate parameter takes a single argument, which itself is a parameter list; the elements that may appear within this list are: up/1, down/1, up_limit/1, and down_limit/1.
The up and down parameters each may take one of three values: true, false, and if_no_solvers. The value true indicates that the request should be propagated upward (or downward); false indicates that it should not be propagated; and if_no_solvers indicates that it should be propagated if there are no local agents that can handle this request (i.e., none that are clients of the same facilitator as the requester).
Given that a goal is to be propagated upward or downward, the up_limit/1 and down_limit/1 parameters can be used to limit the number of levels, of facilitator agents, to which it is propagated. For example, specifying an up_limit of 0 would preclude all upward propagation (the request would go only to the facilitator of the requester, and thus would be no different than specifying up(false)), whereas an up_limit of 1 would allow the requester's facilitator to pass the request upward to its parent facilitator (but no further upward).
The default for the up/1 and down/1 parameters is false. For up_limit/1 and down_limit/1, there is no default value, which means that the number of propagation levels is unlimited.
The following example shows the propagate parameter that would be used if the requester wants its request to be handled by all agents that declare the appropriate solvable, and are clients of its facilitator, or of the parent of its facilitator, or of any other facilitator below that parent in the hierarchy.
oaa_Solve(Goal, [propagate([up(true), up_limit(1), down(true)])])
Note that the propagate parameter does not have any effect when an explicit address has been given, using the address parameter. When an explicit address has been given, the facilitator attempts only to route the request to the agent or agents specified, and does not consider propagation opportunities at all.
These same parameters may also be used with oaa_AddData, oaa_RemoveData, oaa_ReplaceData, oaa_AddTrigger,, and oaa_RemoveTrigger.
Except when a non-default value of the reply parameter is specified, the oaa_Solve/2 procedure blocks until a solution to a query has been found (either in a positive way - success - or a negative way - no solution can be obtained). For this reason, it is sometimes desirable to set a limit on the amount of time a remote agent can use to satisfy a query. The time_limit parameter is used to limit the amount of solve-time to a given number of seconds, with oaa_Solve/2 failing if no solution can be found in this amount of time.
The time_limit parameter encloses a positive real number, as in the following example:
oaa_Solve(Goal, [time_limit(10.5)])which indicates that the responding agent is not to be given any more than 10.5 seconds to respond. If it happens that the responding agent does not respond in the allowed time, the facilitator causes the call to oaa_Solve/2 to fail.
However, it is still possible that the responding agent will return solutions after the time limit has expired. If this happens, the solutions are still returned to the requesting agent; that is, a ev_solved/6 event is sent to the requesting agent. This makes it possible for the requesting agent to make use of the belated response, if it takes the required steps to make use of that event. The way to do this is described in Section 6.8.
oaa_Solve(notify('Adam Cheyer', 'OAA meeting at 3:00'), [])
In providing this service, this agent may call upon a calendar agent ( to determine the whereabouts of the specified recipient), a database agent ( to retrieve the recipient's phone number or email address), and one or more communications agents (e.g., a phone agent, an email agent, or a fax agent). If the phone agent is employed, the notification agent will also call upon a text-to-speech agent, to prepare digitized audio waveforms to be played over the phone line.
In a scenario such as this, where a series of service requests (calls to oaa_Solve) is initiated by a single call to oaa_Solve, it is sometimes helpful to have a means of establishing a context that ties together all of the service requests. The context/1 parameter provides a simple means of doing this.
The value of the context/1 parameter is unconstrained; that is, it may be any ICL atom or expression that is convenient. Whenever a call to oaa_Solve includes context(SomeValue) in its parameter list, that parameter is automatically propagated to all subsequent calls to oaa_Solve resulting from the initial call (regardless of which agent is making the call). In the scenario above, a context/1 parameter passed to the initial call:
oaa_Solve(notify('Adam Cheyer', 'OAA meeting at 3:00'),
[context(message_request_114)])
would be present in each callback that transmits one of the subsequent
service requests. For example, assume that the email agent is selected
for use by the notification agent, and that it provides a solvable
send/3 and defines a callback function send_mail/2, as described
in the example from Section
5.2. Then its callback function will be called like this: send_mail(send(mail, 'Adam Cheyer', 'OAA meeting at 3:00'), [..., context(message_request_114), ...])(The parameters list will also include such things as the from/1 parameter, indicating which agent generated this particular request.)
It is possible for multiple context/1 parameters to appear in a parameter list. If the initial call to oaa_Solve contains multiple contexts, each of them is propagated to subsequent calls. Furthermore, subsequent calls may introduce additional context/1 parameters, in which case these are passed along together with those introduced by earlier calls in the chain.
This may easily be done, using the get_address/1 parameter. Unlike the other oaa_Solve parameters discussed above, get_address takes a variable for its argument. When oaa_Solve returns, this variable will be bound to a list of all agents to which the goal was sent (or, in the case of a compound goal, all agents to which any subgoal was sent). The elements of this list will be local IDs (as described in Section 4.3.7, Agent Names and Addresses).
Because this parameter returns a value, it is called a "return parameter". Another return parameter, closely related to get_address/1, is get_satisfiers/1. Whereas get_address returns all agents to which the goal was sent, get_satisfiers returns only those agents which returned one or more solutions to the goal (or to some subgoal, in the case of a compound goal).
A future enhancement will enable a user to create their own strategies defining frequently-used combinations of parameters.
This behavior may be modified by a parameter list, which may contain some combination of the following parameters:
| cache(T_F) | cache all solutions locally, and if good solutions already exist in
the cache, use the local values instead of making a distributed
request. Default: false. |
| level_limit(N) | highest number of hierarchical levels to climb for
solutions. default: N = 0 (don't climb) |
| address(AgentId) | send request to specific agent, given its name or Addr. If AgentID is 'self', solves the goal locally. |
| reply(Mode) | true: Reply desired. none: No reply desired. Default: true, except when the call to oaa_Solve is a trigger action, in which case it is none. 'none' is used here instead of false, because we anticipate some additional values. |
| blocking(Mode) | true: Block until the reply arrives. : false: Don't block. In this
case, the reply events (ev_solved) can be handled by the user's
app_do_event callback function. Default: true, except when the call to oaa_Solve is a trigger action, in which case it is false. Note that reply(none) overrides blocking(true). |
| callback(Pred) | When blocking(false) and reply(true) are in effect, hence asking for an asynchronous query, this parameter may be used to specify the predicate to be called with the reply event (ev_solved). In the absence of this parameter, the app_do_event callback is used. |
| solution_limit(N) | Limits the maximum number of solutions found to N. |
| time_limit(N) | Waits a maximum of N seconds before returning (failure if no solution found in time). |
| context(C) | Passes a context value through any subsequent solves. |
| parallel_ok(T_F) | if T_F is 'true' (default), multiple agents that can solve the Goal will attempt to work on it in parallel. If 'false', one agent will be selected at a time to solve the goal, until the maximum number of requested solutions (see solution_limit) is found. |
| reflexive(T_F) | If T_F is `true', the Facilitator will consider the originating
agent when choosing agents to solve a request. Default: true. |
| priority(P) | P ranges from 1 (low priority) to 10 (high priority) with a default of 5. |
| flush_events(T_F) | Will flush (dispose of) all events of lower priority currently
queued at the destination agent. These events are lost, and will not be
executed. This parameter should be used with caution!!! Default: false. |
| get_address(X) | Returns a list of addresses (ids) of agents that were asked to solve the goal, or one of its subgoals |
| get_satisfiers(X) | Returns a list of addresses (ids) of agents that succeeded in solving the goal, or one of its subgoals. |
| get_goal_id(X) | Returns the GoalId generated for this solve request. |
| strategy(S) | Shorthand for certain combinations of the above parameters. S is one
of
action = [parallel_ok(false), solution_limit(1)] inform = [parallel_ok(true), reply(none)] |
Remarks: Note that certain combinations of parameters are inconsistent, and are handled as follows: reply(none) overrides blocking(true), reply(none) overrides parallel_ok(false)
All of the above parameters may be used in the "global" parameter list (the
second argument to oaa_Solve), when Goal is non-compound. Most can be used in
the global list with compound goals also. Some of these parameters can also be
used in the NESTED parameter lists of compound goals.
A data solvable can be used privately by an agent, or can be made publicly readable and/or publicly writable, so that other agents have access to it. The level of access is determined by the permissions and the private parameter associated with the solvable.
The library procedures oaa_AddData, oaa_RemoveData, and oaa_ReplaceData are used to read and write data solvables.
A call to any of these causes the agent that provides the data solvable to check its active data triggers, and may result in the firing of one or more of them, as explained in Section 8.3, Trigger Firing Conditions
Note on terminology: In describing these procedures, we use the name clause for the argument that specifies the fact to be added, removed, or replaced. The connotation of clause is actually more general than that of fact, and clause is used deliberately. This is because in future versions of the OAA library, in certain situations, we expect that it may become possible to add, remove, or replace rules in addition to facts. For present purposes, however, clause may be considered synonymous with fact.
Any agent may add data to one of its writable data solvables (whether private or public), or to a publicly writable data solvable of another agent, by calling
oaa_AddData(+Clause, +Params)This causes the the data element Clause to be recorded, in precisely the form given.
Normally, there may be multiple facts recorded for a data solvable, and any number of facts that are exact duplicates of one another. However, note that the creation of multiple facts can be disallowed by the provider of the solvable, by declaring the solvable with the parameter single_value(true). Similarly, the creation of duplicate facts can be disallowed with the parameter unique_values(true).
By default, the data element is recorded following all existing data elements belonging to the same solvable. This means that, in subsequent calls to oaa_Solve, the new data element will be the last fact returned from that solvable. This can be overriden using the at_beginning/1 parameter with the call to oaa_AddData.
By default, a call to this procedure is blocking; that is, the call does not return until an acknowledgement is received, from the facilitator, that the request has been completed by all the appropriate agents. As with oaa_Solve, this procedure can be made non-blocking using the reply parameter, which takes a value of either true or none. Provided that the value of reply is true (the default), a list of agents completing the request may be returned using the get_address parameter.
Any agent may remove data from one of its writable data solvables (whether private or public), or from a publicly writable data solvable of another agent, by calling
oaa_RemoveData(+Clause, +Params)
By default, a call to this procedure removes only the first fact that unifies with Clause, on each agent to which the request is dispatched. However, the parameter do_all(true) can be used to request that all unifying facts be removed.
A call to this procedure is normally blocking; that is, the call does not return until an acknowledgement is received, from the facilitator, that the request has been completed by all the appropriate agents. As with oaa_Solve, this procedure can be made non-blocking using the reply parameter, which takes a value of either true or none. Provided that the value of reply is true, a list of agents completing the request may be returned using the get_address parameter.
Any agent may replace data on one of its writable data solvables (whether private or public), or on a publicly writable data solvable of another agent, by calling
oaa_ReplaceData(+Clause1, +Clause2, +Params).
This causes the facilitator to first remove a data element that unifies with Clause1, and then to record the data element Clause2.
In essence, the effect of this call is the same as that of a call to oaa_RemoveData, followed by a call to oaa_AddData. The difference is that the implementation of oaa_ReplaceData is guaranteed to be atomic; that is, for each agent that is affected by the call to oaa_ReplaceData, nothing can read or write that agent's data store between the occurrence of the replace and add operations.
Although Clause1 and Clause2 normally are facts of the same data solvable, this is not required to be the case. What is required is that each agent receiving the replacement request provides a data solvable that is appropriate for Clause1, and also a data solvable that is appropriate for Clause2.
The do_all/1 parameter, if present, will affect the removal of Clause1, in the same way it does when used with oaa_RemoveData. The at_beginning/1 parameter will affect the addition of Clause2, in the same way it does when used with oaa_AddData.
By default, a call to this procedure is blocking; that is, the call does not return until an acknowledgement is received, from the facilitator, that the request has been completed by all the appropriate agents. As with oaa_Solve, this procedure can be made non-blocking using the reply parameter, which takes a value of either true or none. Provided that the value of reply is true (the default), a list of agents completing the request may be returned using the get_address parameter.
A call to any of these procedures causes the appropriate operation (data addition, removal, or replacement) to take place on one or more agents. The address/1 parameter may be used to specify specific agents on which to effect the operation, including self, parent ( or facilitator), and/or the IDs of peer agents. Section 4.3.7, Agent Names and Addresses details how addresses are specified.
Any agent specified in the address parameter of a call to one of these procedures must already provide the appropriate data solvable (or solvables, in the case of oaa_ReplaceData); otherwise, the call will not affect that agent in any way.
The address/1 parameter is optional. When it is not present, the facilitator will attempt to choose agents in just the same way it does with requests for services ( calls to oaa_Solve/2). That is, it will treat Clause as a goal (Clause1 in the case of oaa_ReplaceData), and select all client agents having a solvable goal that unifies with the clause. By default, this can include the requesting agent (that is, the agent calling oaa_AddData, oaa_RemoveData, or oaa_ReplaceData), unless the requesting agent is explicitly excluded using the reflexive parameter.
In a multiple facilitator configuration, the propagation of data maintenance requests may be controlled using the propagate parameter, as described in Controlling Hierarchical Search.
For example, imagine a scheduling agent that collects information about manufacturing tasks to be completed, and their desired completion times. This scheduling agent could maintain a data solvable, say schedule_request/2, which can be written by several other "tasking agents" (each having responsibility for some part of the manufacturing process).
When a tasking agent adds a new fact to schedule_request/2, that indicates, to the scheduling agent, a new task that needs to be scheduled. Ownership information, which is transparently maintained by the OAA libraries, can be used by the scheduling agent (or by other agents) to keep track of which requests belong to which tasking agents. Of course, it is also possible to maintain this information explicitly, by including it as a field within some declared data solvable, but the transparent maintenance of ownership information adds considerable convenience. For example, when one of the tasking agents goes offline, assuming the parameters for schedule_request have been set properly, the facts owned by that agent are automatically removed from the data store of the scheduling agent.
In addition, it is possible to query just those facts owned by a particular agent, by using the owner parameter of oaa_Solve, as described in section 6.6.
For additional details, see the Reference Manual.
get_satisfiers returns only those agents which indicate that they were able to successfully complete the request. For instance, if an agent calls oaa_RemoveData(SomeFact, ...), that request is sent to all agents that provide the appropriate data solvable. However, if the specified fact is not present on one of these agents, that agent is not considered to have successfully completed the request. That agent's address, then, would be included in the value returned with get_address, but not in the value returned from get_satisfiers.
When a data solvable is publicly readable and writable, it may be thought of as a global data repository, which can be used cooperatively by a group of agents. In combination with the use of triggers, this allows the agents to organize their efforts around a ``blackboard'' style of communication. As explained in Section 5.1.6, Library Procedures for Declaring Solvables, a data solvable can be maintained by a facilitator if desired, at the request of one of its clients.
As an example, the DCG-NL agent (Definite Clause Grammar Natural Language agent), which provides natural language processing services for a variety of its peer agents, expects those other agents to record, on the facilitator, the vocabulary that they are prepared to respond to, with an indication of each word's part of speech, and of the logical form that should result from the use of that word. To make this possible, when it comes online, the DCG-NL agent installs a data solvable for each basic part of speech on its facilitator, using library calls such as this:
oaa_Declare([solvable(noun(Meaning, Syntax), [type(data)], [])], [address(parent)], _)
In the Office Assistant system, a number of agents make use of these services. For instance, the database agent uses the following call to post the noun `boss', and to indicate that the ``meaning'' of boss is the concept `manager':
oaa_AddData(noun(manager, atom(boss)), [address(parent)])
OAA triggers provide a general mechanism for specifying some action to be taken when some set of conditions is met. Each agent can install triggers either locally, for itself, or remotely, on its facilitator or a peer agent. There are four types of triggers :
"Whenever a solution to a goal is returned from the facilitator, send the result to the presentation manager to be displayed to the user."
"When 15 users are simultaneously logged on to a machine, send an alert message to the system administrator. "
To install a trigger, of any type, use the command
oaa_AddTrigger(Type, Condition, Action, Params)
oaa_AddTrigger/4 causes a trigger to be installed on one or more agents. The address/1 parameter may be used to specify specific agents on which to install the trigger, including self, parent ( or facilitator), and/or the IDs of peer agents. Section 4.3.7, Agent Names and Addresses details how addresses are specified.
The address/1 parameter is optional, and its default value depends on the trigger type. With triggers of type comm and time, the default value is ['self'].
If no address/1 parameter is specified for a data or task trigger, the facilitator will attempt to choose agents in just the same way it does with requests for services ( calls to oaa_Solve/2). That is, it will treat Condition as a goal, and select all client agents having a solvable that unifies with the condition. In the case of a data trigger, this solvable must be of type data; in the case of a task trigger, it must be of type trigger. (Trigger solvables are declared specifically for use with task triggers.)
In a multiple facilitator configuration, the propagation of trigger installation (and removal) requests for these types of triggers may be controlled using the propagate parameter, as described in Controlling Hierarchical Search.
Depending upon a trigger type's, its firing conditions are determined by some combination of the Condition argument, the test/1 parameter, and the on/1 parameter.
The Condition argument is used with all four types of triggers. Depending on the trigger type, it specifies what events, data items, or circumstances may cause the trigger to fire.
In the case of a comm trigger, Condition should have the form:
event(FromToAgtId, Content, Params)and should be unifiable with some event that is expected to be sent or received by each agent on which the trigger is to be installed. The meaning of this condition is: When an event unifiable with Condition is sent or received, consider this trigger for firing. The decision to fire may also depend upon the on/1 and test/1 parameters, as described below.
When installing a comm trigger, Params should always be given as a variable; it is the Content argument that actually specifies the event of interest. Params, which will be bound when the trigger is selected, can be used in the trigger action or in a test parameter, if desired.
In the case of a data trigger, the form of Condition depends on whether the trigger monitors addition, removal, or replacement of a data element, as specified by the on/1 parameter (see below). When monitoring addition or removal, Condition should be unifiable with a data solvable of each agent on which the trigger is to be installed. Its meaning is: When a data element unifiable with Condition is added or removed, consider this trigger for firing. (The decision to fire may also depend upon the test/1 parameters, as described below.) When monitoring replacement, Condition specifies both the old and new data elements, within the replace/2 structure. For example:
replace(current_location(RobotId, OldLocation),
current_location(RobotId, NewLocation))
might be used as the Condition of a data trigger designed to
detect changes in location, given the availability of the data solvable
current_location/2. Note that this allows OldLocation and/or
NewLocation to be used in the trigger's action, since both of these
variables will be bound when the trigger fires.
In the cases of comm and data triggers, Condition can also be a variable, which indicates that the trigger should be considered for firing with every event or data modification, respectively.
In the case of a task trigger, Condition is an ICL expression that corresponds to a solvable of type trigger. Its meaning is: When Condition succeeds (on the agent where this trigger is installed), consider this trigger for firing. However, it is important to realize that the 2.x agent library does NOT check this condition (this differs from OAA 1.x libraries). (Nor is it necessary for application code to define an app_do_event callback for a trigger solvable.) The condition must be checked by application code, at whatever times and in whatever ways are appropriate for the application. When an application "offers" a task trigger -- that is, when it declares a solvable of type trigger, it may want to know when such a trigger has been installed, so that it can set up the necessary mechanisms for efficiently checking the task trigger condition. For this purpose, the app_setup_trigger callback is provided. When it is necessary to periodically check a task trigger condition, it is often convenient to use the app_idle callback (in the Prolog library and other non-Java libraries).
When a task trigger condition becomes true, application code is responsible for calling oaa_CheckTriggers/3. oaa_CheckTriggers, in turn, will then check the truth of the test/1 parameter (if there is one), as described below, before firing the trigger. See the Reference Manual for documentation on oaa_CheckTriggers.
For alarm triggers, the Condition parameter should be in the form: time_expr(FromDateTime, ToDateTime, Recurrent) where FromDateTime and ToDateTime look like date(Year,Month-1,Day,Hr,Min,Sec) and Recurrent has the form recurrent(Value,Unit). If the trigger is not a recurrent trigger, the Recurrent field should contain recurrent(0,0).
The on/1 parameter is used only with comm and data triggers, and restricts under what circumstances the trigger is to be selected for firing. For a comm trigger, its value may be either receive, send, a list containing both of these, or a variable. The use of a variable, which has the same effect as a list containing both send and receive, simply means that the trigger should be considered in both situations.
For a data trigger, the value of on/1 may be either add, remove, replace, a list containing any combination of these, or a variable. The values add, remove, and replace correspond to the addition, removal, and replacement, respectively, of a fact belonging to some data solvable, which is maintained by the agent on which the trigger is located. When the value of on is a variable, that is equivalent to the use of the list containing all three values. Note, however, that replace should not be used in combination with either add or remove, unless Condition is a variable. (If Condition is bound, it must be different for replace than for the other two values, as described above.)
See Section 7, Maintaining Data, for information regarding library procedures for adding, removing, and replacing facts of data solvables.
With task and alarm triggers, the value of on/1 may be anything, as it is unused.
The test/1 parameter contains a test which must succeed in order for the trigger to fire, in addition to a successful match of the trigger's condition and/or its on/1 parameter, if present. This test may be any expression that can be evaluated by the ICL interpreter.
The following example illustrates how, in the case of a data trigger, the Condition argument, the on parameter, and the test parameter can all influence a trigger's time of firing.
oaa_AddTrigger(
data,
replace(position(car1, X1, Y1), position(car1, X2, Y2)),
oaa_Solve(some_action),
[on(replace), address(name(position_database)),
test(oaa_Solve((position(target, XT,YT),
distance(X2,Y2,XT,YT,D),
D < 100)))])
In this example, the Condition argument indicates that a data solvable position/3 ( in particular the fact for car1) is to be monitored. The address parameter indicates the trigger is to be installed on an agent named 'position_database', and the on parameter indicates that we are monitoring replacement of the fact. (In this example, it is known that the fact for car1 will be regularly updated with a replacement operation.) As the position of car1 changes, the test of the trigger specifies that if car1's distance to a target becomes less than 100, the trigger should fire.
The recurrence parameter specifies the duration of the trigger. It can take the following values:
Trigger actions take effect either by calling oaa_Solve or by calling oaa_Interpret. You may specify one or the other in the Action argument. That is, the Action argument can be an instance of oaa_Solve/2 or oaa_Interpret/2. In either case, the Goal and Params arguments that you specify will be used when the trigger fires.
For convenience, when you have no parameters to specify, you can also use oaa_Solve/1 or oaa_Interpret/1. Note, however, that the default value of oaa_Solve's reply parameter is different when oaa_Solve appears in a trigger; that is, a default value of none is used, instead of the usual default of true.
Another option is to specify just an ICL Goal as the value of the trigger's Action argument. This provides backwards compatibility with some earlier versions of the OAA libraries, and has the same effect as if Action were specified as oaa_Interpret(Goal).
To remove a trigger, of any type, use the command
oaa_RemoveTrigger(Type, Condition, Action, Params)As with oaa_AddTrigger, Params may contain an address, specifying the agent from which the trigger is to be removed. In the absence of such an address, the trigger removal request is distributed to all relevant agents, just as it is with oaa_AddTrigger.
A call to this procedure causes (at most) one trigger to be removed on each relevant agent -- the first trigger stored whose Type, Condition, and Action unify with those specified in the call. Params is ignored in this making this selection.
Triggers can be installed programmatically, as described above, using the oaa_AddTrigger agent library procedure. Another excellent way of adding triggers (especially task and time triggers) is through natural language. Here are some examples of natural language trigger expressions and their programmatic equivalents:
oaa_AddTrigger(task, arrives(mail, [for('Adam Cheyer'), about(security)]),
notify('Adam Cheyer'),
[recurrence(when)])
oaa_AddTrigger(time,
time_expr(date(98,4,13,13,29,19),date(98,4,13,13,29,19),recurrent(0,0)),
call('David Martin'),
[recurrence(when)])
This trigger will fire on May 13, 1998 at 1:29:19 pm.
oaa_AddTrigger(time,
time_expr(date(96,11,20,13,51,19),date(96,11,25,0,0,0),recurrent(3,minute)),
check(mail),
[recurrence(whenever)])
get_satisfiers returns only those agents which indicate that they
were able to successfully complete the request. At present, with trigger
requests, this will always be the same as the value returned from
get_address. In future versions of OAA, however, it is possible that
agents may be able to refuse trigger requests, in which case the return values
of these two parameters will differ.
The process of implementing a new agent includes the following basic steps:
1. Determine what solvables are to be provided by the agent. These will be declared when connecting to a facilitator (see below), and much of the agent's implementation will be structured around them.
2. Include a copy of the agent library (according to the appropriate language-specific conventions).
3. Optionally, override default behaviors with agent-specific calls and definitions of the following:
* Define an app_done callback procedure, if desired, which provides a hook allowing an agent to clean up after itself when quitting.
* With the app_idle callback, you can define actions to be invoked when no events are in the queue, and a timeout has occurred. (Note: the app_idle callback is not used in the Java library.)
4. Communication, data, task or time triggers may be defined by calling oaa_AddTrigger.
5. The agent must define a callback procedure for each of its procedure solvables. The code defined for each of these callbacks may install local or remote triggers, read or write from the facilitator, post events or queries to the facilitator or to a particular agent, or interface with routines in the application associated with the agent (e.g., the mail program, a database).
6. To open communications with a facilitator, the agent should call the library procedure com_Connect(parent, [], _Address).
parent is the Connection ID. _Address is a variable, since the facilitator's address is usually obtained from the command line, environment variables, or a setup file.
7. To register with a facilitator, the agent should call the agent library procedure oaa_Register(parent, AgentName, Solvables,Params).
8. To start an event loop for the agent, call the agent library procedure oaa_MainLoop.
Please see the Agent Development Tools User Manual for a description of how the process of creating new OAA agents can be partially automated.
Often, a domain agent will serve as an OAA "wrapper" to some existing application, such as to a database or calendar program. A variety of means may be used to enclose an existing application within an agent "wrapper":
Agents that are not written in Prolog will need to parse incoming ICL requests, which use a Prolog syntax. The Agent Library for each of these languages includes a set of ICL parsing procedures to facilitate breaking apart incoming requests into appropriate components.
Included here are several recommendations for programming agents within the OAA.
The agent configuration displayed above in Figure 1 contains a typical arrangement with one facilitator agent and a number of client agents for which that facilitator is responsible. The facilitator knows the capabilities of each of its agents and, given a task to execute, decides how the agents should interact to produce the desired results. However, other network configurations are possible within the OAA, including more complex configurations where multiple facilitator agents can interact.
As noted earlier, the facilitator is just another OAA agent, using the same agent library and communication standards as a domain agent. In the case of a multiple-facilitator configuration, we can think of each facilitator agent as as a "super" agent, capable of solving all goals solvable by its client agents; the facilitator accomplishes this by delegating each incoming goal to one or more of its client agents.
To invoke a facilitator that registers as a client of another facilitator, in addition to serving the needs of its own clients, it is only necessary to tell that facilitator what address to connect to, using oaa_connect on the command line, as an environment variable, or in a setup file, as explained in section 4.6.1.
A number of multiple-facilitator configurations are conceivable within OAA. One issue to consider when designing a network structure of OAA agents is to ensure that circular requests will not occur, with one agent asking another to do a task, and the second trying to accomplish the task by asking the first to do it.
Currently, although it is possible to construct a variety of connection patterns among multiple facilitators, the OAA libraries only provide direct support for a strictly hierarchical (tree) connection pattern, as illustrated in Figure 2. In this connection pattern, when a goal (G) is posted to a local facilitator, that facilitator may consider three different groups of potential solvers: its non-facilitator child agents; its facilitator child agents; and its parent facilitator. The propagate/1 parameter may be used to guide the facilitator as to which groups it chooses from, and at what time. The use of this parameter is explained in Controlling Hierarchical Search.
A hierarchical facilitator connection pattern is often useful in applications where it can mirror some existing organizational structure. In these applications, higher-level facilitators can be used to cover a broader range of domain knowledge, or perhaps serve a larger group of users, than lower-level facilitators. Figure 2 illustrates this sort of application. When a goal (G) is posted to a local facilitator (BB1), and the facilitator agent at BB1 determines that none of its child agents has the requisite knowledge to satisfy the goal, it propagates the goal to a more senior facilitator agent (BB4) in the hierarchy. (Note that non-facilitator agents, which may be connected to any of the facilitators, are not shown in the figure.) This more senior facilitator agent maintains a knowledge base of the goals that its lower level facilitators can solve. When a senior facilitator agent receives such a request, it in turn propagates the request down to its child agents (which themselves are facilitator agents), which either have immediate child agents which can evaluate the goal, or can themselves pass on the goal to another subsidiary facilitator agent. In the case illustrated in Figure 2, BB4 determines that none of its subsidiary facilitators can handle the goal, and thus sends the goal to its superior facilitator agent (BB5). BB5 passes the goal to BB6, which in turn passes it to BB9.
When such a "referred goal" is passed through the hierarchy of facilitators, it is accompanied by information about the address of the originating facilitator (indicated by the BB1 subscript on G). This "continuation" information enables the solution information (whether answers or failure) to be sent back to the originating facilitator. Also, the identity of the responding agent (a non-facilitator client of BB9) is sent back to the originator, so that future queries of the same type may be addressed directly to that agent if desired.
Note that the behavior pattern just described does not occur with the default values of the propagate parameter (the default values indicate no propagation. However, this behavior pattern can easily be achieved by using the following propagate parameter:
oaa_Solve(Goal, [propagate([down(true), up(if_no_solvers)])])
Figure 2: Multiple facilitators arranged in a hierarchy
Most sections of this Developer's Guide are concerned either with the design and structure of individual agents, or with the interactions that take place between agents in an operating system. Here we consider, given a collection of agents that have been selected and/or constructed to work together as a system, what needs to happen to set that system in motion, and to insure that it continues to operate.
We describe, below, how to make use of the OAA's execution manager, Start-It, which is designed to minimize the effort involved in invoking and monitoring a system. However, there are times, especially during debugging, when it is important to be able to start or stop an agent (or a system of agents) ``manually''; that is, from the command line of the agent's execution platform.
In starting an individual agent, there are only two general requirements to remember. First, the agent must be able to obtain the correct host and port of its facilitator; this is normally obtained from the setup file. Second, the agent must request a connection and register with its facilitator; this is normally accomplished by a call to com_Connect/2, followed by a call to oaa_Register/3.
In starting up an entire system, the only general requirement to remember is that each facilitator must be started up before its client agents. More precisely, the facilitator must be listening to its assigned port before any of its clients attempt to make a connection.
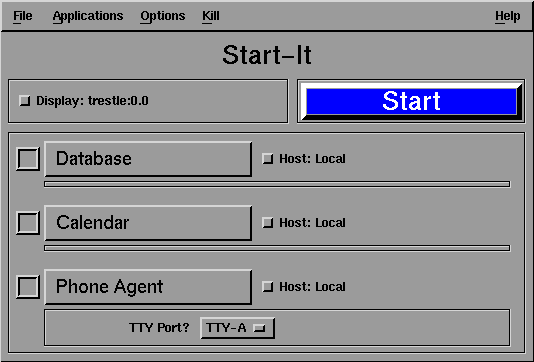
Figure 3: Start-It's user interface
startit [options]For example, the instance of Start-It shown in Figure 3 was invoked using
startit oaa.configAs Start-It is itself an agent, it attempts to connect to a facilitator when it is invoked. Thus, before invoking Start-It, you must ensure that a facilitator is running at the host and port that are currently indicated in the relevant setup file.
Invoking Start-It does not cause any other agents to start up immediately. Rather, its interface provides controls that allow other agents to be invoked.
Start-It takes an optional command line argument -no_expect. If this option is given on startup, Start-It will not try to make use of the `expect' program, which requires that TCL be installed on your system. Expect solves some minor problems with Start-It:
If the -autostart option is given, all agents controlled by the Start-It window will automatically be run as soon as Start-It is ready to do so, as if the user had pressed the big blue START button. This feature could be useful if you want to create a login for a particular demo where all agents (including Start-It) would begin executing as soon as X-Windows initializes.
As shown in the figure, Start-It always provides the Display control and the large button labeled Start. The Display control shows which machine will be used to display the windows in which the various agents are invoked (this is not necessarily the same machine on which the agents are run). Clicking in the small box causes a choice list to appear, which can be used to either choose or type in a different display. The default value is ``Local'', which means the machine that Start-It is running on.
The Start button causes Start-It to invoke all agents currently being displayed in its main window.
Start-It is capable of maintaining multiple projects, or collections of agents, in a single configuration file. By choosing a project from the Projects menu, all agents belonging to the project become visible in Start-It's main window, and all agents not belonging to the project are no longer displayed. To display the list of all agents defined in the configuration file, the user may select the Global from the Projects menu.
Beneath the Display and Start controls in the main window, there are groups of controls for individual agents. For each agent specified in the configuration file, Start-It provides a status box, a basic menu, and a host selector.
When Start-It has been asked to invoke an agent, the agent's status box is colored either yellow (the agent is initializing but is not yet ready to interoperate), green (the agent is connected to a facilitator and ready to interoperate), or red (the agent has died or is not functioning normally).
An agent's basic menu is accessed by clicking on the large button labeled with the agent's name (such as the button labeled ``Database'' in Figure 3). When this is done, a menu is displayed containing the four commands Hide, Show Options, Start, and Kill. These commands are used as follows:
The Host control is used to specify the machine on which the agent is to execute. Clicking in the small box causes a choice list to appear, which can be used to either choose or type in a different host. The default value is ``Local'', which means the machine that Start-It is running on.
#------------------------------------------------------ # Employee Database Agent #------------------------------------------------------ appname Database oaaname employee_db.root appdir /home/zuma1/OAA/demo.bin appline ./d2 end #------------------------------------------------------ # Calendar Agent #------------------------------------------------------ appname Calendar oaaname calendar.root appdir /home/zuma1/OAA/demo.bin preline setenv ENV_VAR something appline ./c onready inform_ui(calendar, ready) ondisconnect [inform_ui(calendar, disconnect), reinit(all)] end
The specifications shown here for each of the agents, `appname', `appdir', and `appline', are required to be present for each process to be started. If the process is an oaa agent, 'oaaname' should be defined as well.
`projectlist' is a line that must be given at the head of a configuration file (before the definition of any processes), specifying all projects defined in the configuration file. A project can be thought of as a way of partitioning the processes into groups that can be viewed as together in Start-It's main window.
The rational for onready and ondisconnect is that there are times when agents need to perform initialization handshaking with respect to one another. If one agent is restarted for some reason, other agents might like to know this information. Although each agent could setup individual triggers to detect the coming and going of agents it is interested in, in some cases it is much simpler and cleaner to put these project level interactions directly in the Start-It config file, letting Start-It to the work (it knows already who is connected and what their state is).
It is also possible, in the configuration file, to specify agent-specific menus or other interface elements for use in selecting operational parameters for various agents. The interface elements are used to allow the user to specify values for different variables which can be referenced in the appline. Command line variables should be written in the form ${varname}.
The following example (for the phone agent shown in Figure 3) allows the user to choose a tty-port (A or B), which is added to the command line of the phone agent.
#------------------------------------------------------
# Phone Agent
#------------------------------------------------------
appname Phone Agent
oaaname phone
appdir /home/zuma1/OAA/demo.bin
appline ./phone ${tty-port}
menu tty-port TTY Port?
option ttya TTY-A
option ttyb TTY-B
end
end
There are five types of interface components:
menu varname Text To Be Displayed
option return_value1 Option Text 1
line
option return_value2 Option Text 2
default return_default Default Text
end
The `line' option is used to create separators within the menu, and is
optional. If the `default' field is not specified, the first option listed
will be the default value.
toggle varname Text To Be Displayed true-value Value To Be Returned If TRUE true-label Label To Be Displayed when TRUE false-value Value To Be Returned If FALSE false-label Label To Be Displayed when FALSE set endAll parameters for the toggle control are optional. If the `set' parameter is given, the toggle defaults to have value `TRUE', `FALSE' otherwise.
text varname Text To Be Displayed
value Default Start Value
size WidthInChars
end
All parameters for the text control are optional. The `value' field
provides the initial value contained by the text field, and `size' indicates
how wide the text field is in characters.
Variables are expanded ONLY IF they are sourrounded with curly braces in this fashion: ${variable}. If they occur without braces (e.g. $variable) they are treated like any other string, and simply passed verbatim ($ sign and all) to the shell started up by the rsh. They will, of course, get expanded "on the other end" of the rsh, so you should be sure some such shell variable will exist there (either because you know it's defined by the shell itself, or in your .cshrc, or in the app's "preline" directive).
One is ${globalDisplay}, which refers to the contents of the display widget in the top left corner of the startit GUI.
The second is ${Host} (notice capitalization), which refers to the contents of the "Host:" widget (located next to each Application Name button on the startit GUI). You may use the form ${application:Host} to specify an application other than the current one (see "Specifying The Application Name" below).
${application_name:selector}
Whenever a ":" exists within your variable name, this method of
resolving the variable is used exclusively.
application_name is one of the applications in your config file, as specified on an "appline" directive. It may contain spaces, or any other character, except a colon. selector is the name of one of the selector widgets (e.g. toggle, menu, text, toggle-text-menu) as specified by the second argument of one of those directives.
EXAMPLE:
This makes the host entry of "My Agent" start out to be
the same host as whatever the "Push To Talk" is set to:
appname My Agent
host ${Push To Talk:Host}
# This will echo the host "Test 1" is running on, since
# "$HOST" doesn't get expanded by startit at all
appdir /
appname Test 1
appline echo $HOST
end
# This will echo the host "startit" is running on, since
# startit will expand "${HOST}" as its own environment var
appdir /
appname Test 2
appline echo ${HOST}
end
# This will echo the contents of "Test 3"'s "Host:" selector
appdir /
appname Test 3
appline echo ${Host}
end
# This will echo the contents of "Test 1"'s "Host:" selector
appdir /
appname Test 4
appline echo ${Test 1:Host}
end